walkinglabs/hands-on-modern-rl
RL course that makes you break PPO before reading the paper
It exists to replace 'formula first, API later' with broken experiments that teach you why PPO actually works.
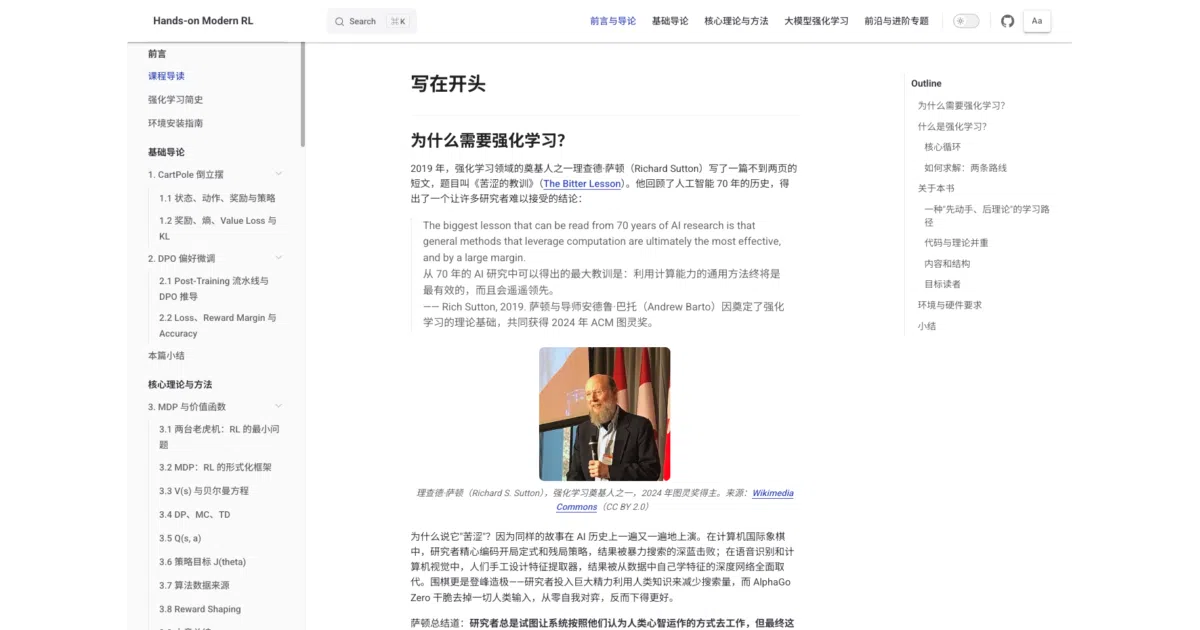
Velocity · 7d
+4.7
★ / day
Trend
↘cooling
star history
What it does
Hands-On Modern RL is an open courseware project that teaches reinforcement learning by having you run experiments first and meet the math second. The curriculum starts with classic control and Atari games, then climbs through PPO and Actor-Critic all the way to LLM post-training pipelines like DPO, GRPO, and RLVR, plus multi-turn agentic systems. It packages runnable Python examples, training metric visualizations, and line-by-line code annotations into a browsable site with auto-generated PDFs.
The interesting bit
Most courses sanitize the path to success; this one treats training collapse, reward hacking, KL drift, and OOM failures as core material rather than footnotes. The authors also explicitly reject black-box API tutorials in favor of readable implementations you are expected to break and modify.
Key highlights
- Practice-first structure: every topic starts with runnable code and observable training curves, then introduces MDPs, Bellman equations, and policy gradients as explanations for behavior.
- Coverage spans classic deep RL (
DQN,REINFORCE,PPO) and modern alignment (RLHF,DPO,GRPO,RLVR), plus vision-language model RL and tool-use agents. - Debugging is first-class: entropy decay, reward hacking, and evaluation blind spots are discussed alongside the algorithms themselves.
- Math review appendices lower the barrier to entry; you need PyTorch fluency, not graduate analysis.
- Bilingual content: the site and auto-built PDFs are available in English and Chinese.
Caveats
- The authors warn that the course was created with AI assistance and has not been fully reviewed, so it may contain factual errors or code that does not run as expected.
- Several chapters remain under construction, and the roadmap shows major sections like Unity embodied RL and Diffusion RL are still pending.
- The CC BY-NC-SA 4.0 license restricts commercial use.
Verdict
Grab this if you are an ML engineer or self-learner moving from supervised learning into RL, LLM alignment, or agent building. Skip it if you need a peer-reviewed, guaranteed-correct reference; this is actively evolving courseware that expects you to open issues and pull requests when you spot mistakes.
Frequently asked
- What is walkinglabs/hands-on-modern-rl?
- It exists to replace 'formula first, API later' with broken experiments that teach you why PPO actually works.
- Is hands-on-modern-rl open source?
- Yes — walkinglabs/hands-on-modern-rl is an open-source project tracked on heatdrop.
- What language is hands-on-modern-rl written in?
- walkinglabs/hands-on-modern-rl is primarily written in Python.
- How popular is hands-on-modern-rl?
- walkinglabs/hands-on-modern-rl has 3.3k stars on GitHub and is currently cooling off.
- Where can I find hands-on-modern-rl?
- walkinglabs/hands-on-modern-rl is on GitHub at https://github.com/walkinglabs/hands-on-modern-rl.