tatsu-lab/stanford_alpaca
How to teach a LLaMA to follow instructions for $500
Stanford's recipe for turning open-weights LLaMA into an instruction-following model using synthetic data generated by... OpenAI's own API.
Not currently ranked — collecting fresh signals.
star history
What it does Stanford Alpaca is a fine-tuned LLaMA model that follows natural-language instructions. The repo ships the 52K instruction dataset, the code that generated it, and a straightforward Hugging Face training script to reproduce the model. You can also recover the Alpaca-7B weights from a released diff if you already have the base LLaMA-7B weights.
The interesting bit
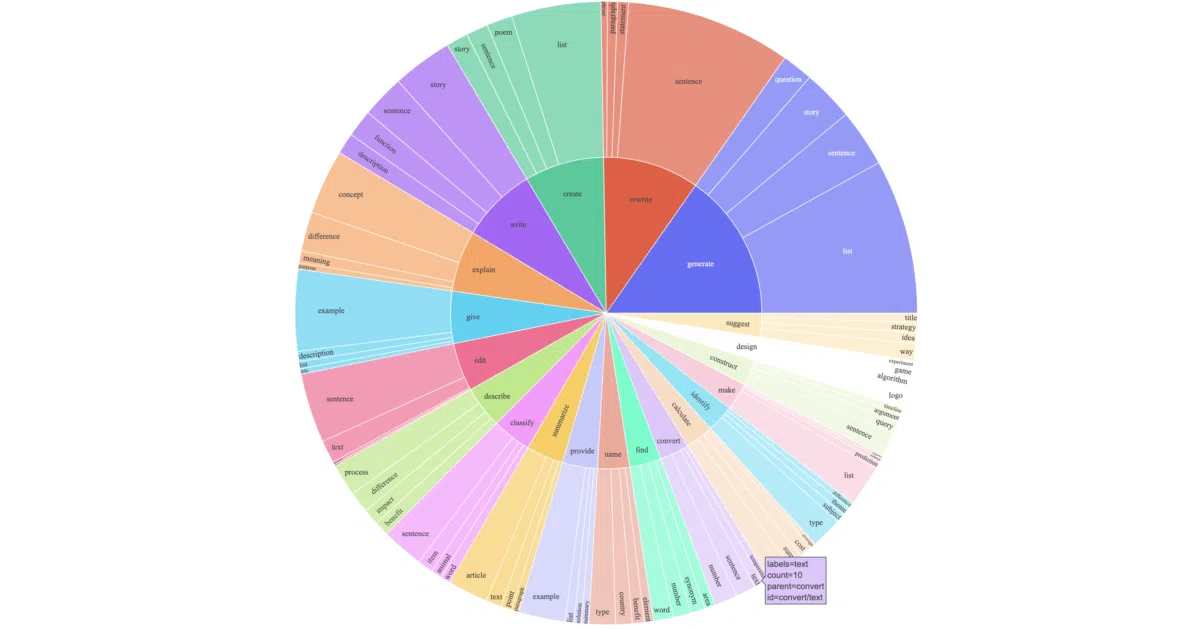
The dataset was synthesized by asking text-davinci-003 to generate instructions and answers, then using that OpenAI-generated data to fine-tune a competitor open model. The authors call this “self-instruct” with modifications; the economics are hard to ignore—less than $500 in API costs versus the millions spent training base models. They also note, with admirable candor, that there is a “slight error” in their generation prompt and point to a community PR to fix it.
Key highlights
- 52K unique instruction-following examples, ~40% with optional context inputs
- Generation pipeline uses aggressive batch decoding (20 instructions per call) to cut API costs
- Training recipes for LLaMA-7B/13B and OPT-6.7B via FSDP or DeepSpeed, with CPU-offload and LoRA options for memory-constrained setups
- Weight diff release lets you reconstruct Alpaca-7B without redistributing full weights
- Explicitly research-only: CC BY-NC 4.0 on data and weight diffs
Caveats
- The live demo is “suspended until further notice”
- The authors warn they “have not yet fine-tuned the Alpaca model to be safe and harmless”
- Base LLaMA weights remain gated by Meta; you cannot train without them
Verdict Worth studying if you want to understand how cheap synthetic data can bootstrap instruction following in smaller open models. Skip it if you need a production-ready, safety-tuned model or lack access to the LLaMA weights.
Frequently asked
- What is tatsu-lab/stanford_alpaca?
- Stanford's recipe for turning open-weights LLaMA into an instruction-following model using synthetic data generated by... OpenAI's own API.
- Is stanford_alpaca open source?
- Yes — tatsu-lab/stanford_alpaca is open source, released under the Apache-2.0 license.
- What language is stanford_alpaca written in?
- tatsu-lab/stanford_alpaca is primarily written in Python.
- How popular is stanford_alpaca?
- tatsu-lab/stanford_alpaca has 30.3k stars on GitHub.
- Where can I find stanford_alpaca?
- tatsu-lab/stanford_alpaca is on GitHub at https://github.com/tatsu-lab/stanford_alpaca.