snexus/llm-search
RAG with a YAML file and a healthy distrust of simple vector search
A local document search system that layers on every retrieval trick in the book—hybrid search, re-ranking, HyDE, multi-query—then exposes it all through an MCP server for your IDE.
Not currently ranked — collecting fresh signals.
star history
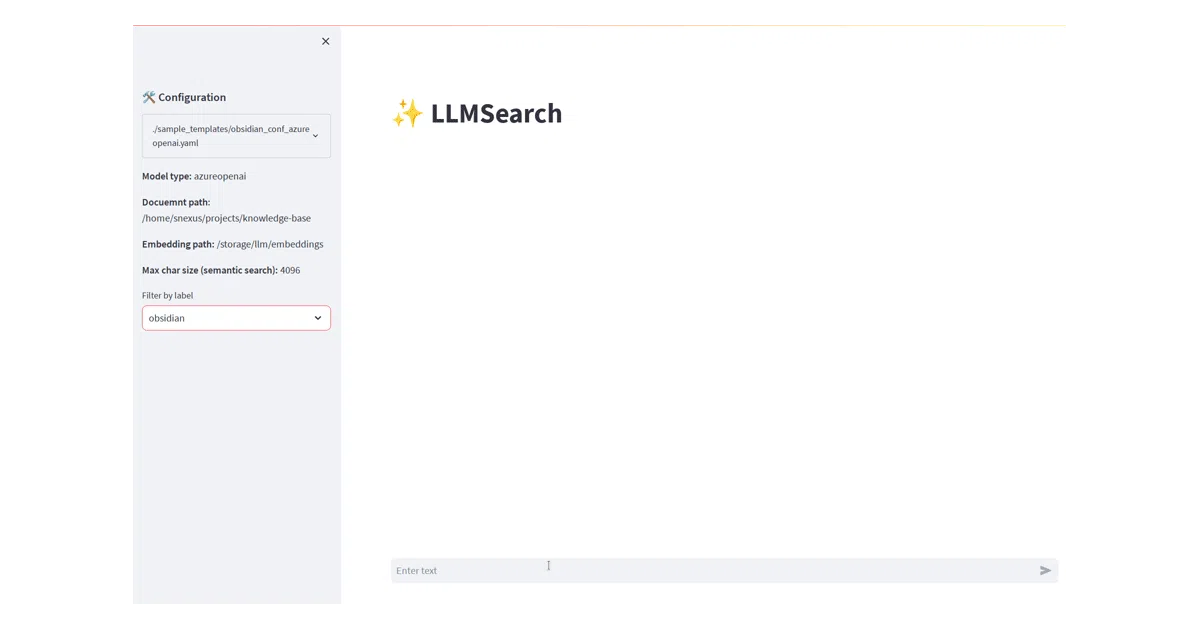
What it does
pyLLMSearch ingests your local documents (PDFs, markdown, Word files, and more) and turns them into a queryable knowledge base. You configure it with YAML, point it at a folder, and ask questions via a Streamlit UI, a FastAPI endpoint, or an MCP server that plugs into Cursor, Windsurf, or VS Code Copilot.
The interesting bit
The author clearly thinks basic RAG is a starting point, not a destination. The system stacks improvements like a paranoid researcher: SPLADE sparse embeddings mixed with dense vectors, cross-encoder re-ranking, HyDE for when you don’t know the jargon yet, and multi-query expansion inspired by RAG Fusion. Even the markdown parser gets special treatment—splitting on headings and cleaning image links instead of dumb chunking.
Key highlights
- Incremental indexing: add documents without rebuilding the entire embedding store
- Hybrid search: dense (ChromaDB) + sparse (SPLADE) with re-ranking via
bge-reranker-v2-m3orzerank-2 - HyDE support with an honest warning that it “significantly alters” result quality
- MCP server via SSE, so your IDE can query your document base directly
- Table parsing via
gmftor Azure Document Intelligence; optional image parsing via Gemini - Chat history with question contextualization
- LiteLLM + Ollama compatibility for local model hosting
Caveats
- The README warns that HyDE can backfire if you don’t understand what you’re enabling
- “Tested on up to few gigabytes” suggests you shouldn’t throw enterprise-scale archives at it blindly
- Jupyter Notebook as the repo language hints the core may be research-grade Python rather than a polished package
Verdict
Worth a look if you’re building a personal or team knowledge base and want retrieval improvements without writing the glue yourself. Skip if you need a managed, scalable enterprise solution—this is a configurable toolkit, not a service.
Frequently asked
- What is snexus/llm-search?
- A local document search system that layers on every retrieval trick in the book—hybrid search, re-ranking, HyDE, multi-query—then exposes it all through an MCP server for your IDE.
- Is llm-search open source?
- Yes — snexus/llm-search is open source, released under the MIT license.
- What language is llm-search written in?
- snexus/llm-search is primarily written in Jupyter Notebook.
- How popular is llm-search?
- snexus/llm-search has 659 stars on GitHub.
- Where can I find llm-search?
- snexus/llm-search is on GitHub at https://github.com/snexus/llm-search.