lucidrains/native-sparse-attention-pytorch
DeepSeek’s Native Sparse Attention, rebuilt in PyTorch
It ports DeepSeek’s block-sparse attention to PyTorch so you can trade dense self-attention FLOPs for memory-friendly block compression and selection.
Not currently ranked — collecting fresh signals.
star history
What it does
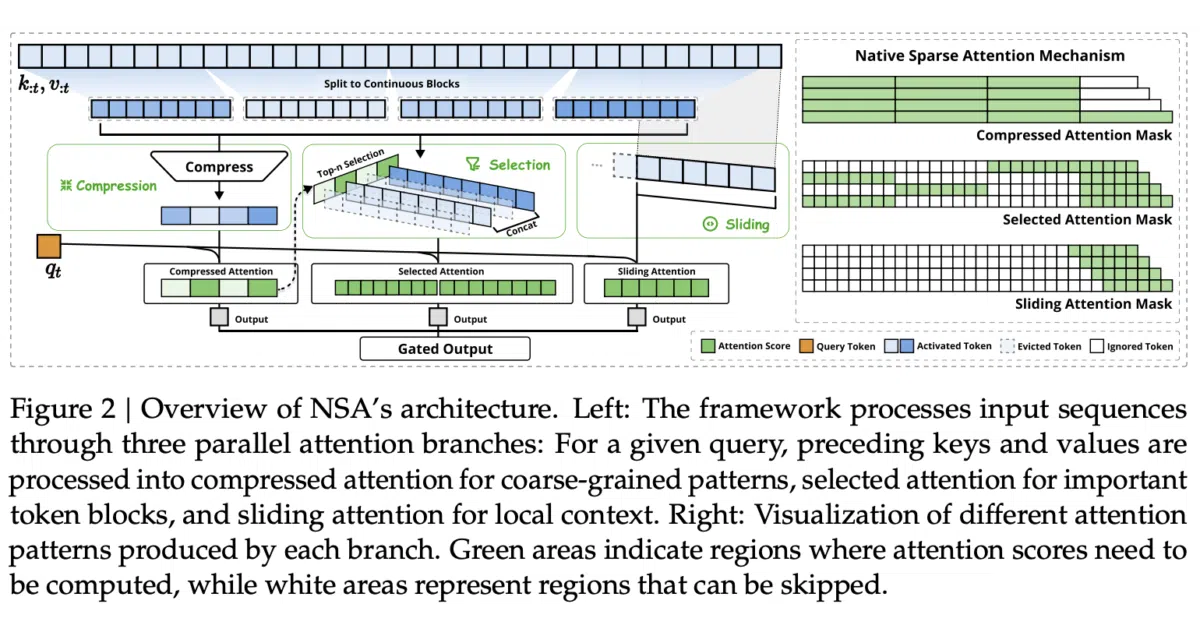
This repo implements the sparse attention pattern from DeepSeek’s Native Sparse Attention paper. It provides a SparseAttention module that replaces standard self-attention with a mix of sliding windows, compressed blocks, and selected blocks, plus an Enwik8 training script to check that the setup actually learns.
The interesting bit
The author credits PyTorch Flex Attention and Triton for enabling rapid prototyping without raw CUDA hacking. He also notes this is his final open-source release while at Meta, giving the repo a slightly valedictory air.
Key highlights
- Reproduces the attention pattern from DeepSeek’s arXiv:2502.11089 paper.
- Credits PyTorch
Flex Attentionfor rapid prototyping without hand-written kernels. - Exposes tunable block sizes via
compress_block_size,selection_block_size, andnum_selected_blocks. - Includes an Enwik8 language modeling example to verify training works.
- Community fixes have already corrected compression hyperparameters and added a memory access guard.
Caveats
- The README is essentially a quickstart: it lists hyperparameters but does not explain how the blocks interact, so you will need the paper for intuition.
- The author describes the project as his last open-source release under Meta, with no further roadmap promised.
Verdict
Worth cloning if you want a readable PyTorch reference for sparse attention research. Skip it if you need a production-grade kernel or a self-contained tutorial on the algorithm.
Frequently asked
- What is lucidrains/native-sparse-attention-pytorch?
- It ports DeepSeek’s block-sparse attention to PyTorch so you can trade dense self-attention FLOPs for memory-friendly block compression and selection.
- Is native-sparse-attention-pytorch open source?
- Yes — lucidrains/native-sparse-attention-pytorch is open source, released under the MIT license.
- What language is native-sparse-attention-pytorch written in?
- lucidrains/native-sparse-attention-pytorch is primarily written in Python.
- How popular is native-sparse-attention-pytorch?
- lucidrains/native-sparse-attention-pytorch has 809 stars on GitHub.
- Where can I find native-sparse-attention-pytorch?
- lucidrains/native-sparse-attention-pytorch is on GitHub at https://github.com/lucidrains/native-sparse-attention-pytorch.