lm-sys/FastChat
The open-source stack behind Chatbot Arena
FastChat is the serving and evaluation platform that powers the most influential LLM leaderboard on the internet.
Not currently ranked — collecting fresh signals.
star history
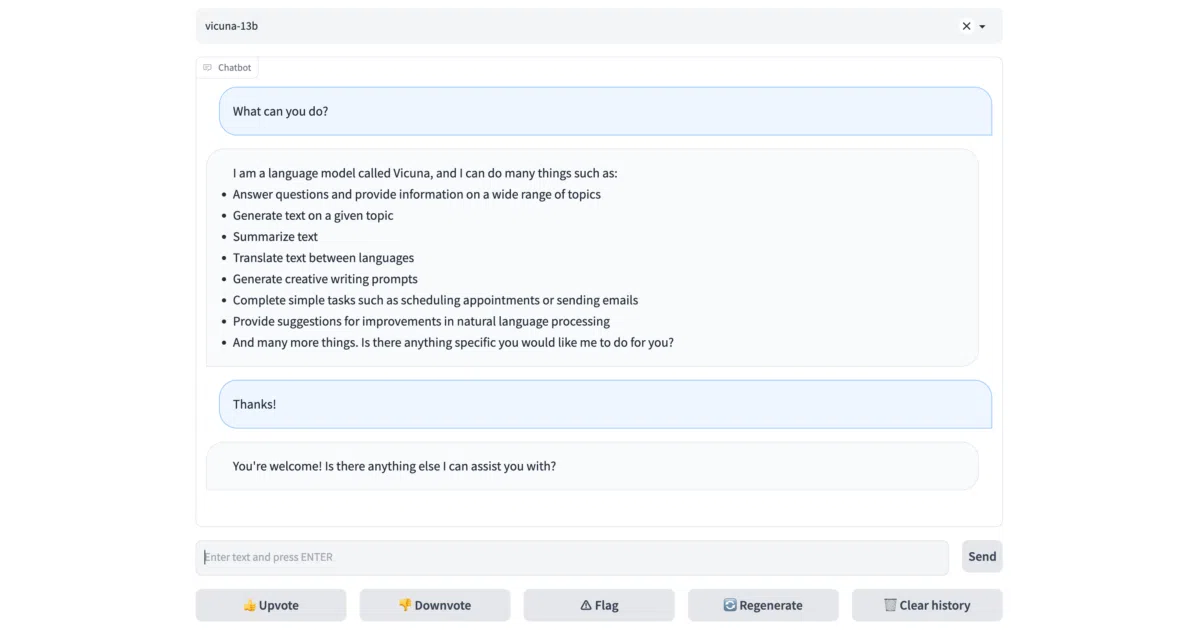
What it does FastChat is a Python toolkit for training, serving, and evaluating LLM chatbots. It bundles a CLI, a Gradio web UI, an OpenAI-compatible REST API, and a distributed controller-worker architecture for hosting multiple models. It also ships with the training recipes and evaluation benchmarks (MT-Bench) used to build Vicuna and LongChat.
The interesting bit The same code that runs your local Vicuna-7B chat also serves 10 million+ requests for 70+ models on Chatbot Arena. That is unusual: most serving frameworks are either research toys or opaque production systems, but FastChat is both the release repo and the production backbone. The Arena’s 1.5M human preference votes are collected through side-by-side battles, then turned into an Elo leaderboard — a sports-ranking approach applied to model evaluation.
Key highlights
- Distributed serving with controller + model workers, plus a Gradio web UI and OpenAI-compatible API
- Broad hardware support: NVIDIA, AMD ROCm, Apple Silicon Metal, Intel XPU/Arc, Ascend NPU, and CPU with AVX512/AMX acceleration
- Quantization options: 8-bit compression, GPTQ 4-bit, AWQ 4-bit, ExLlama V2, plus CPU offloading via bitsandbytes
- Vicuna weights (7B–33B, 4K and 16K context) and LongChat (32K context) available on Hugging Face
- MT-Bench multi-turn evaluation set and the LMSYS-Chat-1M real-world conversation dataset
Caveats
- CPU offloading requires Linux and bitsandbytes, which is noted as a platform limitation
- The README mentions
--style richas experimental and warns it “may not work properly on certain terminals” - Some sections (API docs, fine-tuning details) are referenced but not shown in the truncated README
Verdict Worth a look if you need to self-host multiple LLMs with a unified API, or if you want to reproduce the Vicuna training pipeline. Less compelling if you are already committed to vLLM or TGI for high-throughput serving and do not need the evaluation or fine-tuning pieces.
Frequently asked
- What is lm-sys/FastChat?
- FastChat is the serving and evaluation platform that powers the most influential LLM leaderboard on the internet.
- Is FastChat open source?
- Yes — lm-sys/FastChat is open source, released under the Apache-2.0 license.
- What language is FastChat written in?
- lm-sys/FastChat is primarily written in Python.
- How popular is FastChat?
- lm-sys/FastChat has 39.5k stars on GitHub.
- Where can I find FastChat?
- lm-sys/FastChat is on GitHub at https://github.com/lm-sys/FastChat.