labmlai/annotated_deep_learning_paper_implementations
Paper implementations that actually explain themselves
A curated library of 60+ deep learning papers with side-by-side code and annotations, because reading arXiv shouldn't require a PhD in suffering.
Velocity · 7d
+14
★ / day
Trend
↗accelerating
star history
What it does
This repo pairs clean PyTorch implementations of neural network papers with literate explanations, rendered side-by-side on a companion website. Think of it as a well-commented codebase that escaped into a textbook — covering transformers, GANs, reinforcement learning, diffusion models, optimizers, and enough normalization layers to make a statistician weep.
The interesting bit
The format matters more than the quantity. Each implementation is designed to be read, not just executed: code on one side, math and intuition on the other. The project treats deep learning papers as living documents rather than frozen artifacts.
Key highlights
- 60+ implementations spanning transformers (ViT, Switch, RETRO, Flash Attention), diffusion (Stable Diffusion, DDPM), GANs (StyleGAN2, CycleGAN), RL (PPO, DQN with all the bells), and recent optimizers like Sophia-G
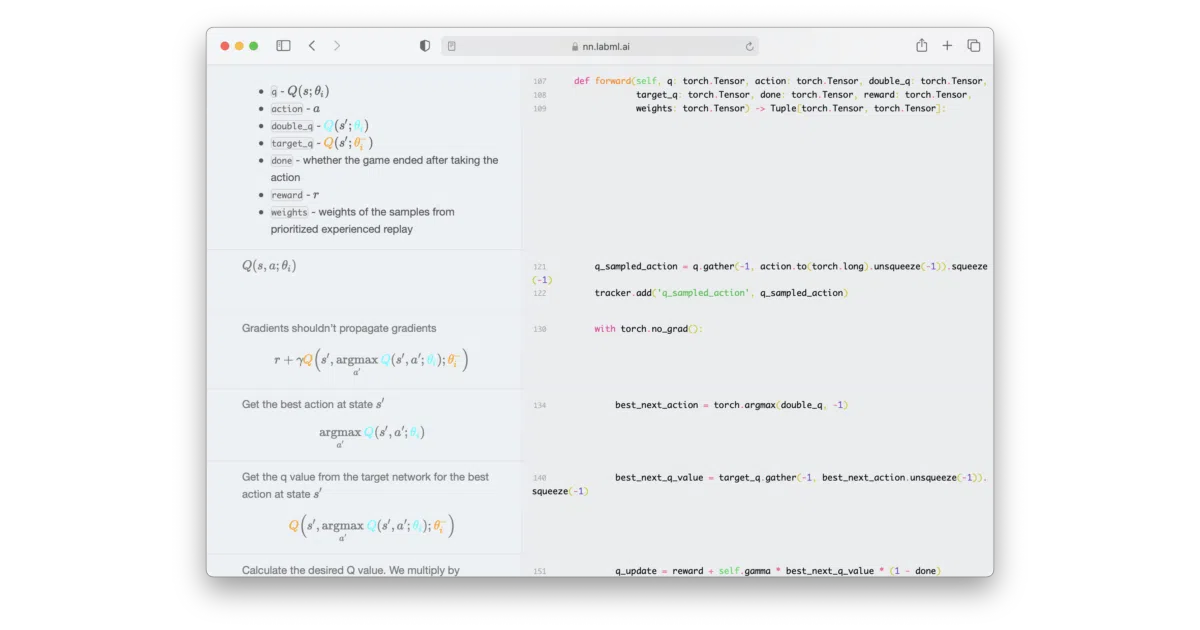
- Side-by-side web rendering at nn.labml.ai — the README screenshot shows DQN with explanations adjacent to code
- Active maintenance with new papers added almost weekly
- Installable via
pip install labml-nn - Includes practical scaling notes (Zero3, LLM.int8(), GPT-NeoX finetuning on 48GB GPUs)
Caveats
- The README is essentially a table of contents; depth and quality of individual implementations must be verified per-paper
- “Simple PyTorch implementations” is the stated goal — production robustness is not
Verdict
Ideal for researchers and engineers who need to understand why a paper works before using it. Skip if you need battle-tested training pipelines or are already comfortable reading raw paper appendices as bedtime material.
Frequently asked
- What is labmlai/annotated_deep_learning_paper_implementations?
- A curated library of 60+ deep learning papers with side-by-side code and annotations, because reading arXiv shouldn't require a PhD in suffering.
- Is annotated_deep_learning_paper_implementations open source?
- Yes — labmlai/annotated_deep_learning_paper_implementations is open source, released under the MIT license.
- What language is annotated_deep_learning_paper_implementations written in?
- labmlai/annotated_deep_learning_paper_implementations is primarily written in Python.
- How popular is annotated_deep_learning_paper_implementations?
- labmlai/annotated_deep_learning_paper_implementations has 67.2k stars on GitHub and is currently accelerating.
- Where can I find annotated_deep_learning_paper_implementations?
- labmlai/annotated_deep_learning_paper_implementations is on GitHub at https://github.com/labmlai/annotated_deep_learning_paper_implementations.