kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference
Skip the GPU: Local Llama 2 for Document Q&A
A tutorial reference implementation for running quantized open-source LLMs on consumer CPUs to answer questions over private documents.
Not currently ranked — collecting fresh signals.
star history
What it does
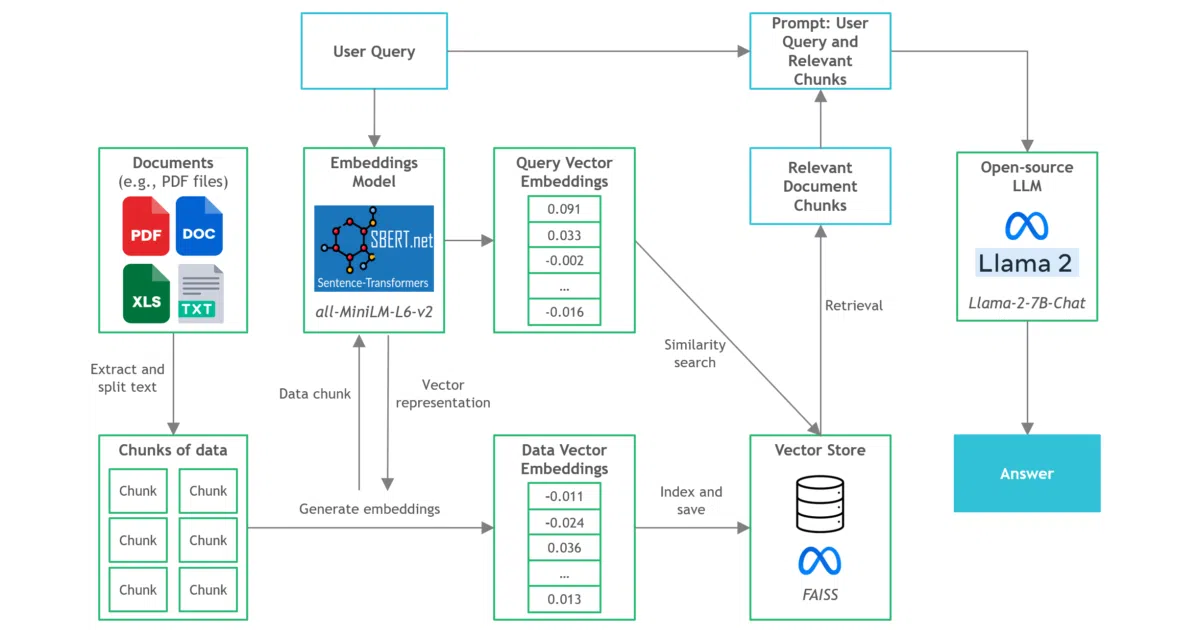
This repository is a tutorial and reference implementation for running a retrieval-augmented document Q&A pipeline entirely on CPU. It ingests PDFs—demoed with a 177-page Manchester United annual report—into a FAISS vector store using all-MiniLM-L6-v2 embeddings, then answers natural-language questions via a quantized Llama-2-7B-Chat model. Think of it as a working recipe rather than a framework: the code shows exactly how to wire LangChain, C Transformers, and GGML together so standard hardware can handle inference without dialing an API.
The interesting bit The project’s real value is demystifying local CPU inference. It demonstrates that a complete retrieval-augmented generation pipeline—embedding, vector search, and LLM generation—can run on standard hardware without third-party API calls, using nothing more exotic than a quantized GGML build of Llama 2.
Key highlights
- Runs Llama-2-7B-Chat on CPU via C Transformers and GGML, no GPU required
- End-to-end RAG pipeline: PDF ingestion, FAISS vector store, semantic retrieval, and local LLM generation
- Uses
sentence-transformersfor embeddings and LangChain to orchestrate components - Includes a detailed write-up on TowardsDataScience walking through the architecture
- CLI interface: pass a query string to
main.pyand get an answer
Verdict Worth a look if you’re evaluating self-hosted LLMs for privacy-sensitive document search and want a complete, working CPU baseline. Skip it if you are looking for a production-ready framework rather than a learning reference.
Frequently asked
- What is kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference?
- A tutorial reference implementation for running quantized open-source LLMs on consumer CPUs to answer questions over private documents.
- Is Llama-2-Open-Source-LLM-CPU-Inference open source?
- Yes — kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference is open source, released under the MIT license.
- What language is Llama-2-Open-Source-LLM-CPU-Inference written in?
- kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference is primarily written in Python.
- How popular is Llama-2-Open-Source-LLM-CPU-Inference?
- kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference has 971 stars on GitHub.
- Where can I find Llama-2-Open-Source-LLM-CPU-Inference?
- kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference is on GitHub at https://github.com/kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference.