gy910210/rnn-from-scratch
RNN guts exposed: no framework, just NumPy and chain rule
A from-scratch walkthrough that treats backprop through time as a computation graph problem, not a math ritual.
Not currently ranked — collecting fresh signals.
star history
What it does
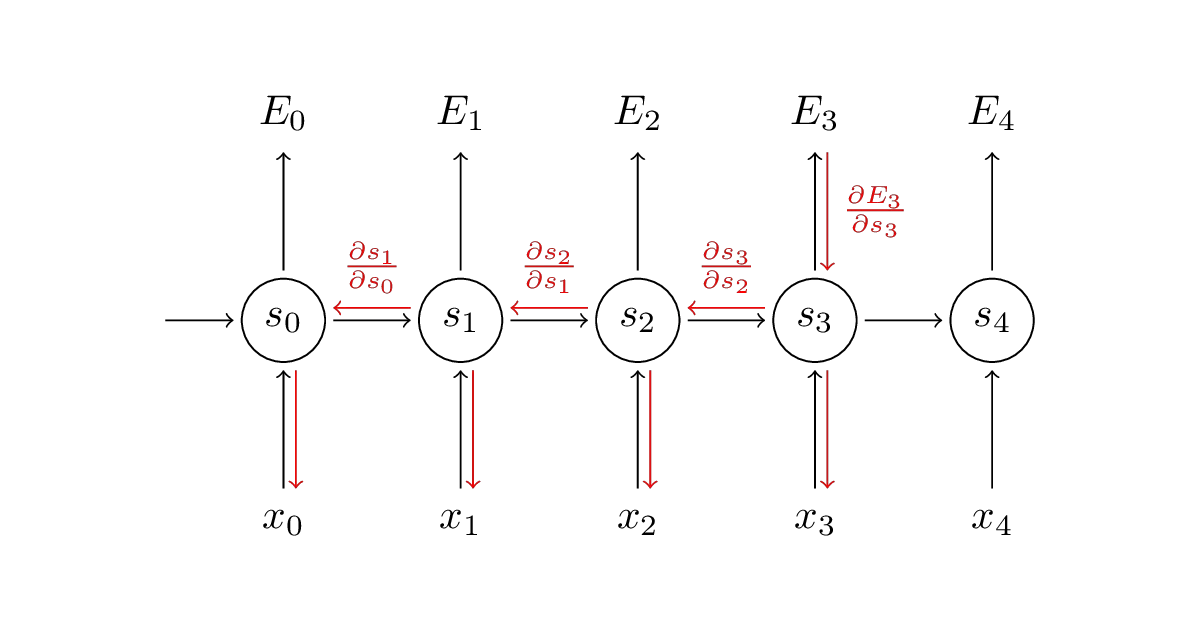
This repo implements a vanilla RNN language model using only NumPy. It walks through forward propagation, cross-entropy loss, and SGD training, with all the gate-level operations—multiply, add, tanh, softmax—written out explicitly as classes with forward and backward methods.
The interesting bit The author frames Backpropagation Through Time as ordinary backprop on an unrolled computation graph, then simplifies it by grouping operations into composite units. It is a pedagogical trick: instead of hand-deriving scary partial derivatives, you let the graph structure do the bookkeeping.
Key highlights
- Pure NumPy implementation with explicit
MultiplyGate,AddGate,Tanh, andSoftmaxprimitives - BPTT truncated to a configurable window (
bptt_truncate=4) to keep the unrolled graph manageable - Xavier-style initialization scaled by incoming connection count
- Code mirrors a companion “neural network from scratch” repo, so the progression from feedforward to recurrent is intentional
Caveats
- The README trails off mid-sentence during the SGD section (
evaluate_loss_is cut off), so the full training loop is incomplete in the source - No performance numbers, dataset details, or convergence plots are shown; it is strictly a tutorial skeleton
Verdict Grab this if you are teaching RNNs or finally want to see BPTT without PyTorch’s autograd hiding the wires. Skip it if you need a production language model or GPU acceleration.
Frequently asked
- What is gy910210/rnn-from-scratch?
- A from-scratch walkthrough that treats backprop through time as a computation graph problem, not a math ritual.
- Is rnn-from-scratch open source?
- Yes — gy910210/rnn-from-scratch is an open-source project tracked on heatdrop.
- What language is rnn-from-scratch written in?
- gy910210/rnn-from-scratch is primarily written in Python.
- How popular is rnn-from-scratch?
- gy910210/rnn-from-scratch has 529 stars on GitHub.
- Where can I find rnn-from-scratch?
- gy910210/rnn-from-scratch is on GitHub at https://github.com/gy910210/rnn-from-scratch.