datascale-ai/opentalking
A talking-head framework that actually ships with a mock mode
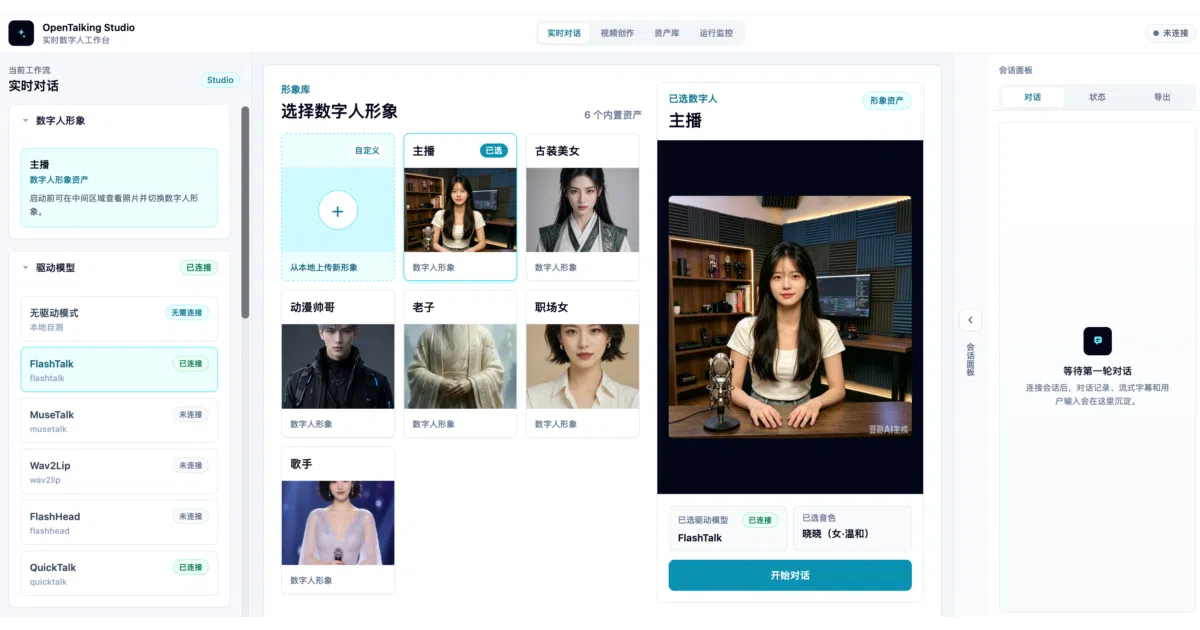
OpenTalking wires up LLM, TTS, STT, and WebRTC into a real-time digital human pipeline you can run on a single GPU—or zero GPUs, if you just want to test the plumbing.
Velocity · 7d
+175
★ / day
Trend
↗accelerating
star history
What it does
OpenTalking is an orchestration framework for real-time AI avatars. It handles the full conversation chain: speech-to-text, LLM response, text-to-speech with voice selection, lip-sync video generation, and WebRTC streaming to a browser. The project explicitly calls itself a “digital human production line” (数字人产线编排), not a model itself.
The interesting bit
The deployment spectrum is unusually honest. There’s a --mock mode that runs the entire audio/text/WebRTC pipeline with a static placeholder face—no GPU, no model weights, no crying. Once that works, you graduate to local models (QuickTalk on a 3090/4090, or lighter Wav2Lip), or remote high-quality inference via OmniRT. The README even provides SHA256 checksums for model weights, which suggests someone actually tried this more than once.
Key highlights
- Modular backends: swap between
mock,local,direct_ws, or OmniRT remote inference without rewriting the frontend - Local-first options: QuickTalk and Wav2Lip run on consumer GPUs; full local audio (SenseVoice + CosyVoice) is documented for air-gapped setups
- WebRTC-native: streaming audio/video to browser is core, not bolted-on
- Sane defaults:
edgeTTS works without API keys; LLM keys are provider-specific and don’t share a fallback - React 18 + FastAPI + Python 3.10+ stack;
uvfor dependency management
Caveats
- The “industrial-grade” claim in the repo description is aspirational; the project has ~1K stars and a roadmap still in progress
- QuickTalk requires manual weight downloads from HuggingFace plus InsightFace
buffalo_lsetup—several steps that can fail on network issues - LLM defaults point to Chinese cloud providers (DashScope, DeepSeek, Doubao); you’ll need to rewire for other regions
Verdict
Worth a look if you’re building a real-time avatar product and need the glue layer done for you. Skip it if you want a single pretrained model you just call—this is plumbing, not porcelain.
Frequently asked
- What is datascale-ai/opentalking?
- OpenTalking wires up LLM, TTS, STT, and WebRTC into a real-time digital human pipeline you can run on a single GPU—or zero GPUs, if you just want to test the plumbing.
- Is opentalking open source?
- Yes — datascale-ai/opentalking is open source, released under the Apache-2.0 license.
- What language is opentalking written in?
- datascale-ai/opentalking is primarily written in Python.
- How popular is opentalking?
- datascale-ai/opentalking has 2.5k stars on GitHub and is currently accelerating.
- Where can I find opentalking?
- datascale-ai/opentalking is on GitHub at https://github.com/datascale-ai/opentalking.