TIGER-AI-Lab/VLM2Vec
Teach Qwen2-VL to embed images, video, and documents
Because maintaining separate embedding models for images, video, and documents is a headache that a single fine-tuned VLM can solve.
Not currently ranked — collecting fresh signals.
star history
What it does
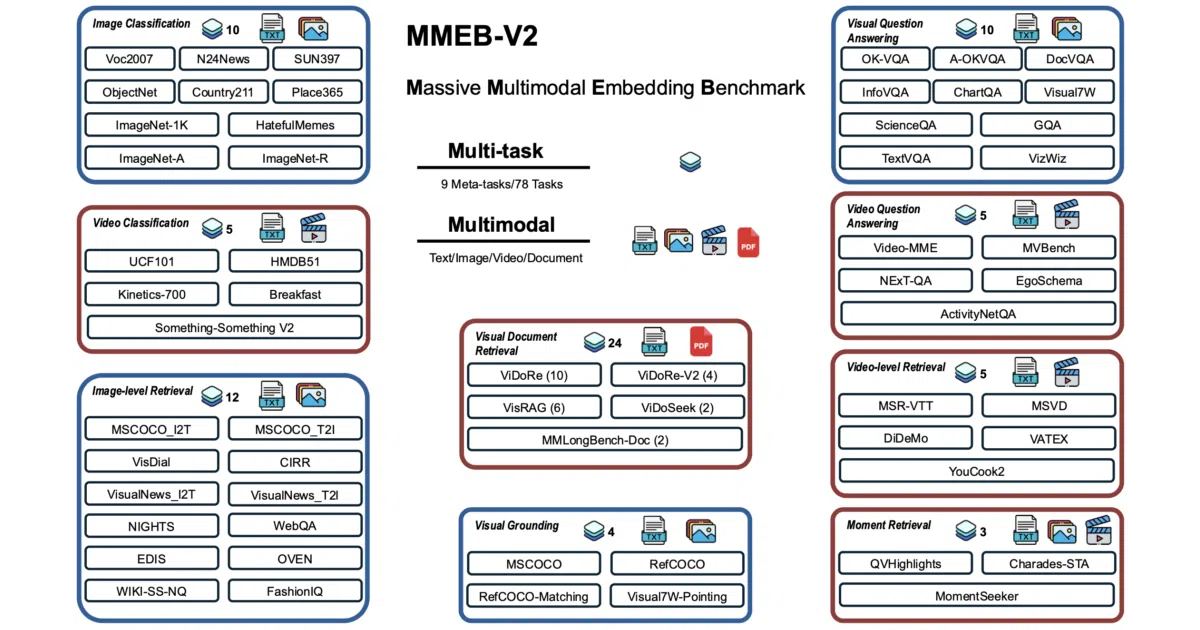
VLM2Vec-V2 is a training and evaluation framework that fine-tunes Qwen2-VL to emit a single fixed-dimensional embedding for any mix of text, image, video, or visual document inputs. It ships with MMEB-V2, a 78-task benchmark spanning retrieval, classification, and QA across all three visual modalities, and the authors report that the resulting model outperforms specialized baselines on every category.
The interesting bit
Rather than gluing together separate encoders, the project uses instruction-guided contrastive training directly on the VLM backbone, with an interleaved sub-batching strategy to keep learning stable when mixing images, videos, and long-form documents in the same batch. The quietly useful part is the standardized YAML configs and pluggable dataset loaders that make the unification reproducible.
Key highlights
- One model handles text, images, video, and visual documents in a shared embedding space.
- Built on Qwen2-VL, which natively supports interleaved text-visual sequences and variable resolutions.
- MMEB-V2 covers 78 datasets, including video moment retrieval and visual document retrieval.
- Training data mixes video-language, visual document, and image-text sources with interleaved sub-batching.
- DDP evaluation is supported and reportedly finishes within hours on multiple GPUs.
- Offline inference is available through vLLM integration.
Caveats
- Upgrading from V1 is intentionally destructive: the README warns you to back up local work and hard-reset the main branch to sync with the rewritten codebase.
- Reproducing baseline comparisons requires manual workarounds, including an older
transformersrelease for GME and single-GPU batches for MomentSeeker. - V2 currently publishes only a 2B-parameter checkpoint; larger models remain on the archived V1 branch.
Verdict
Worth exploring if you are building cross-modal search or RAG and want one retriever instead of a zoo of specialized encoders. Skip it if you need a mature, production-ready API or only care about text embeddings.
Frequently asked
- What is TIGER-AI-Lab/VLM2Vec?
- Because maintaining separate embedding models for images, video, and documents is a headache that a single fine-tuned VLM can solve.
- Is VLM2Vec open source?
- Yes — TIGER-AI-Lab/VLM2Vec is open source, released under the Apache-2.0 license.
- What language is VLM2Vec written in?
- TIGER-AI-Lab/VLM2Vec is primarily written in Python.
- How popular is VLM2Vec?
- TIGER-AI-Lab/VLM2Vec has 667 stars on GitHub.
- Where can I find VLM2Vec?
- TIGER-AI-Lab/VLM2Vec is on GitHub at https://github.com/TIGER-AI-Lab/VLM2Vec.