TIGER-AI-Lab/OpenResearcher
A 30B model that beats GPT-4.1 at deep research—fully open
OpenResearcher publishes the whole recipe: data, model, training code, and evaluation, so you can replicate or extend deep-research agents without proprietary APIs.
Not currently ranked — collecting fresh signals.
star history
What it does
OpenResearcher is a fully open-source pipeline for training agentic LLMs to perform long-horizon web research. It includes a 30B-A3B model, a 96K-turn trajectory dataset distilled from GPT-OSS-120B, a self-built retriever over an ~11B-token corpus, and evaluation frameworks for benchmarks like BrowseComp-Plus and GAIA. The goal is to let anyone reproduce—and improve—deep-research agents without depending on closed commercial systems.
The interesting bit
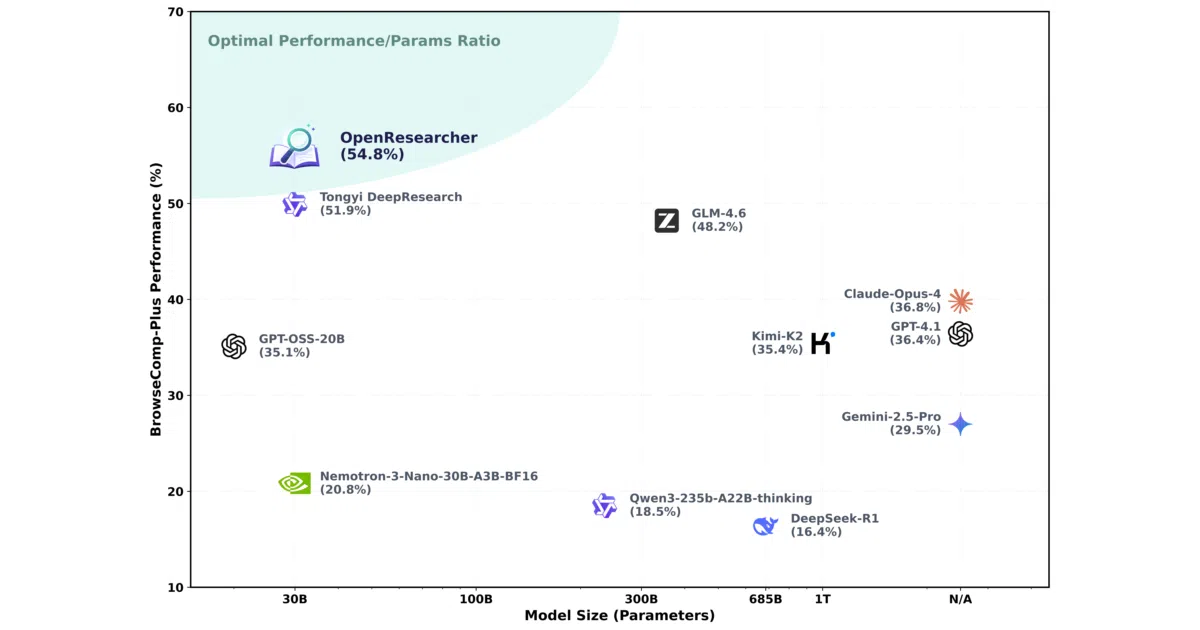
The project achieves 54.8% on BrowseComp-Plus, which the README claims surpasses GPT-4.1, Claude Opus 4, Gemini 2.5 Pro, DeepSeek-R1, and Tongyi-DeepResearch. NVIDIA has adopted the data for its Nemotron 3 Ultra model and NeMo Data Designer. The retriever runs locally, so training doesn’t require paid search APIs—an unusual cost-cutting move in this space.
Key highlights
- Full stack is open: dataset, 30B-A3B model weights, training code, distillation recipe, and evaluation framework
- Self-hosted dense retrieval over ~11B tokens eliminates external search API dependency for training
- Scores 54.8% on BrowseComp-Plus; also evaluated on BrowseComp, GAIA, and xbench-DeepResearch
- NVIDIA Nemotron family and NeMo Data Designer have adopted the data
- Hardware baseline is 8× A100 80GB, though other setups are possible with parameter tweaks
Caveats
- The README is sparse on architectural details for the 30B-A3B model (the “A3B” suffix is unexplained)
- Evaluation comparisons against closed models are reported by the authors, not independently verified
- BrowseComp-Plus local search requires separate embedding model deployment and significant GPU resources
Verdict
Worth studying if you’re building research agents and need a reproducible baseline, or if you’re skeptical of black-box “deep research” features and want to inspect the gears. Skip if you need something that runs comfortably on consumer hardware or want a polished end-user product rather than a research artifact.
Frequently asked
- What is TIGER-AI-Lab/OpenResearcher?
- OpenResearcher publishes the whole recipe: data, model, training code, and evaluation, so you can replicate or extend deep-research agents without proprietary APIs.
- Is OpenResearcher open source?
- Yes — TIGER-AI-Lab/OpenResearcher is an open-source project tracked on heatdrop.
- What language is OpenResearcher written in?
- TIGER-AI-Lab/OpenResearcher is primarily written in Python.
- How popular is OpenResearcher?
- TIGER-AI-Lab/OpenResearcher has 796 stars on GitHub.
- Where can I find OpenResearcher?
- TIGER-AI-Lab/OpenResearcher is on GitHub at https://github.com/TIGER-AI-Lab/OpenResearcher.