THUDM/slime
Wiring Megatron to SGLang without the wrapper bloat
It keeps RL post-training from collapsing into a tangle of disconnected trainers, rollout services, and agent frameworks by wiring Megatron and SGLang into one tight loop.
Velocity · 7d
+16
★ / day
Trend
↘cooling
star history
What it does
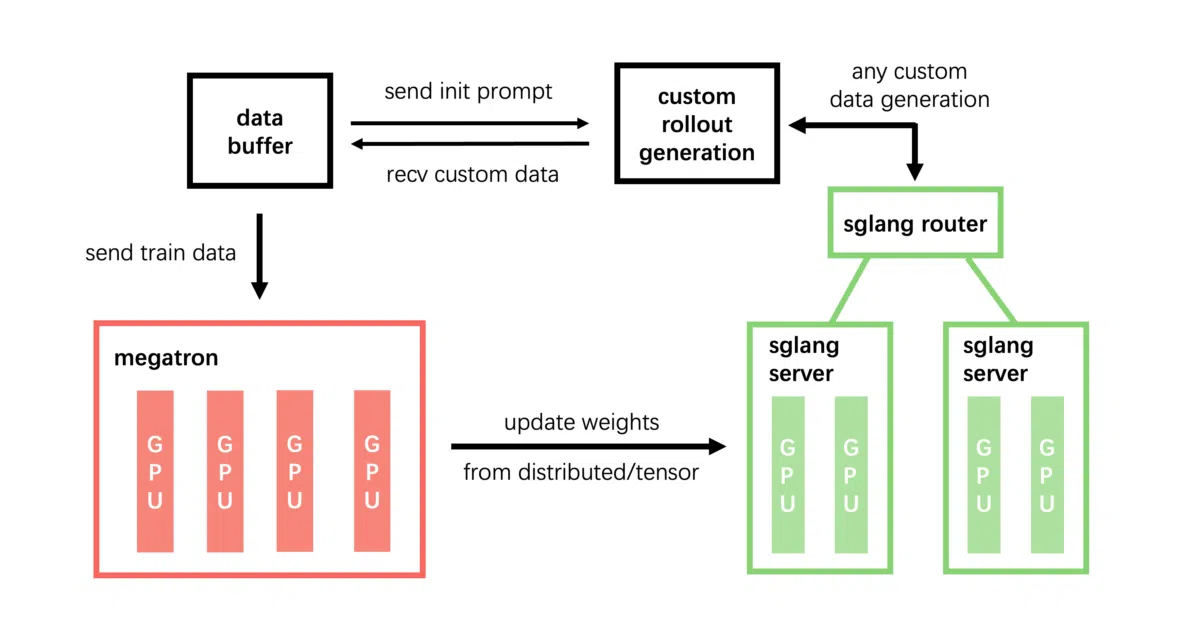
It is an LLM post-training framework for reinforcement learning at scale. It stitches Megatron-LM training and SGLang inference into a single dataflow—training, rollout generation, reward computation, and environment interaction all pass through the same Data Buffer rather than splintering into separate services. The goal is a tight loop that is small enough to understand but hardened enough to run production-grade post-training.
The interesting bit
Instead of wrapping its engines in thick abstraction layers, the framework passes arguments straight through to Megatron and SGLang; prefix the latter with --sglang- and it just works. This native-by-design choice means upstream optimizations arrive immediately, and the project can focus on the RL loop, dataflow, and the unglamorous but critical work of correctness: reproducibility, fault tolerance, tracing, and CI.
Key highlights
- Battle-tested behind the GLM-5 family and supports Qwen, DeepSeek V3/R1, and Llama 3.
- Agentic workflows—multi-agent rollouts, search/RAG, sandboxed coding agents—plug into the standard Data Buffer without forking the training kernel.
- First-class infrastructure hygiene: CPU unit tests, GPU end-to-end tests, contract tests for customization hooks, and dedicated docs for debugging, profiling, and trace viewing.
- Ecosystem projects include omni-modal RL (Relax), physics Olympiad models (P1), and GPU kernel generation (TritonForge).
Caveats
- Deeply opinionated about its stack: if you are not using Megatron for training and SGLang for rollout, this framework is not built for you.
- The intentional single-backend focus means you get SGLang-specific features directly, but switching to vLLM or TensorRT-LLM would require leaving the framework.
Verdict
Worth a look if you are running large-scale RL post-training and want a validated, extensible loop rather than a bag of scripts. Skip it if you need a multi-backend inference abstraction or a lightweight research toy.
Frequently asked
- What is THUDM/slime?
- It keeps RL post-training from collapsing into a tangle of disconnected trainers, rollout services, and agent frameworks by wiring Megatron and SGLang into one tight loop.
- Is slime open source?
- Yes — THUDM/slime is open source, released under the Apache-2.0 license.
- What language is slime written in?
- THUDM/slime is primarily written in Python.
- How popular is slime?
- THUDM/slime has 7.6k stars on GitHub and is currently cooling off.
- Where can I find slime?
- THUDM/slime is on GitHub at https://github.com/THUDM/slime.