Relaxed-System-Lab/Flash-Sparse-Attention
Reordering GPU loops to cut sparse attention’s padding waste
A Triton kernel rewrite that swaps loop orders so Native Sparse Attention stops wasting cycles padding small GQA groups to satisfy hardware constraints.
Not currently ranked — collecting fresh signals.
star history
What it does
Flash Sparse Attention is a Triton-based kernel implementation for Native Sparse Attention (NSA), targeting the “selected attention” module that dominates NSA’s runtime. It plugs into existing LLM training and prefill pipelines on modern NVIDIA Ampere and Hopper GPUs without altering the underlying sparse attention algorithm.
The interesting bit
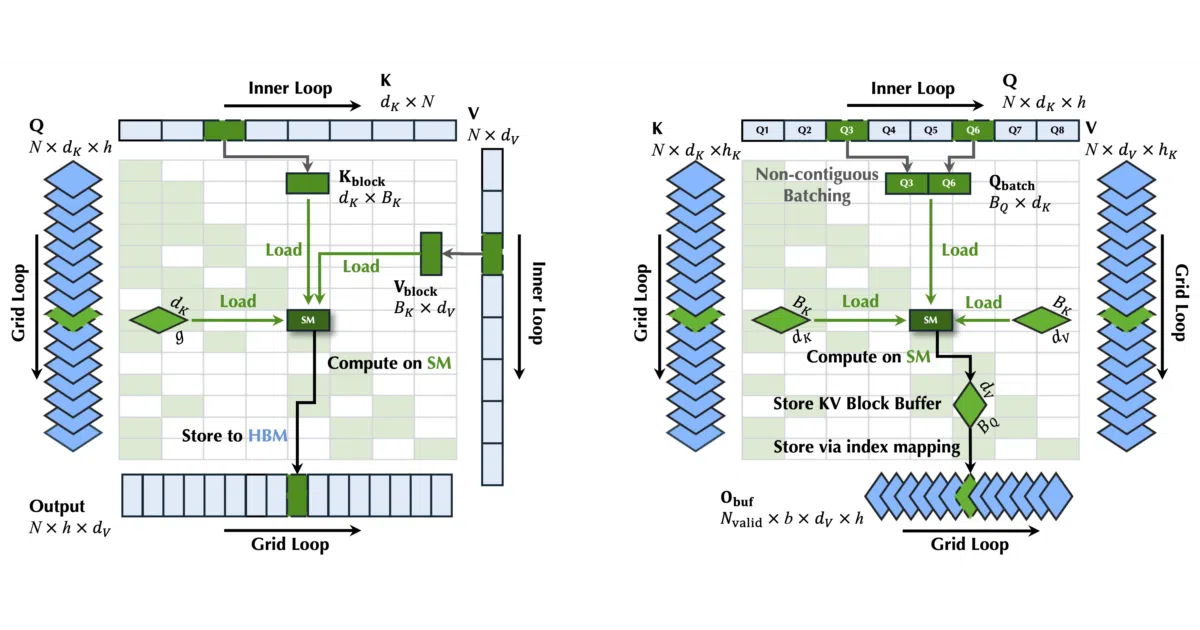
The original NSA kernel loops over query tokens outside and KV blocks inside; when GQA group sizes drop below eight, the kernel must pad matrices to meet NVIDIA warp-level MMA and Triton block-dimension minimums. FSA flips the loop nesting—KV blocks outside, queries inside—and splits the work across a main kernel, a reduction kernel, and an online softmax kernel. This avoids both the padded waste and atomic contention when accumulating partial results across blocks.
Key highlights
- Targets the small-GQA regime (group sizes 1–7) where padding overhead hurts most; transparently falls back to the original NSA kernel for group sizes of 8 or larger.
- Splits computation into three stages to eliminate atomic additions and reduce memory traffic for padded data.
- Supports
fp16andbf16, head dimensions up to 256, and GQA group sizes from 1 to 16 on A100, H100, H200, and compatible cards. - Ships with benchmarking scripts that verify correctness and measure latency and memory against both NSA and full Flash Attention.
- One-step decoding is available in a preview branch; an online profiling module that toggles between NSA and FSA is marked as upcoming.
Caveats
- Production decoding support is still beta-grade; the mainline code is currently validated for training and prefill only.
- Requires recent NVIDIA Ampere or Hopper hardware—older GPUs are out of scope.
- The online profiling module mentioned in the roadmap has not yet been released.
Verdict
Worth a look if you are training long-context models with small GQA configurations and want to recover the kernel efficiency that NSA leaves on the table. Skip it if you need mature decoding today, run on non-NVIDIA hardware, or already use GQA group sizes where the original NSA kernel is competitive.
Frequently asked
- What is Relaxed-System-Lab/Flash-Sparse-Attention?
- A Triton kernel rewrite that swaps loop orders so Native Sparse Attention stops wasting cycles padding small GQA groups to satisfy hardware constraints.
- Is Flash-Sparse-Attention open source?
- Yes — Relaxed-System-Lab/Flash-Sparse-Attention is open source, released under the Apache-2.0 license.
- What language is Flash-Sparse-Attention written in?
- Relaxed-System-Lab/Flash-Sparse-Attention is primarily written in Python.
- How popular is Flash-Sparse-Attention?
- Relaxed-System-Lab/Flash-Sparse-Attention has 621 stars on GitHub.
- Where can I find Flash-Sparse-Attention?
- Relaxed-System-Lab/Flash-Sparse-Attention is on GitHub at https://github.com/Relaxed-System-Lab/Flash-Sparse-Attention.