Rafael1s/Deep-Reinforcement-Learning-Algorithms
32 RL algorithms, 21 environments, one giant spreadsheet of notebooks
A curated matrix of deep-RL experiments where every cell is a Jupyter notebook with training logs.
Not currently ranked — collecting fresh signals.
star history
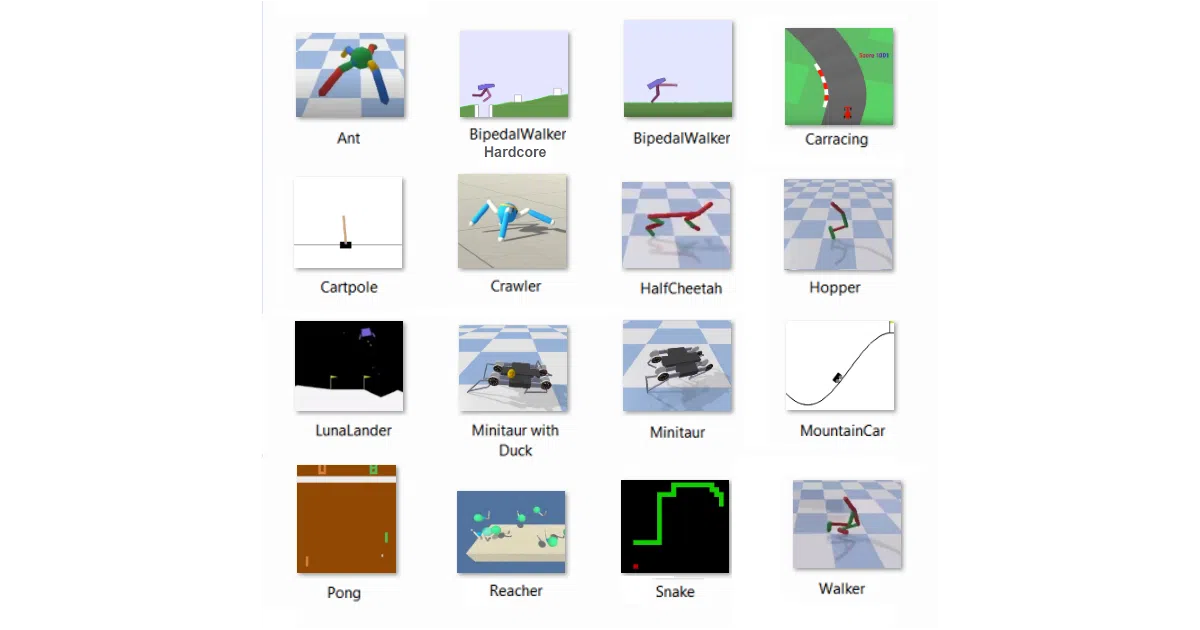
What it does This repo maps algorithms against environments in a grid: rows are OpenAI Gym and PyBullet worlds (CartPole to BipedalWalkerHardcore), columns are methods from Q-learning up through SAC and TD3. Each intersection is a self-contained Jupyter notebook with a training log, so you can watch an agent learn (or stumble) cell by cell.
The interesting bit The author treats reinforcement learning like a controlled experiment rather than a leaderboard chase. Same environment, multiple algorithms—BipedalWalker gets TD3, PPO, SAC, and A2C—so you can actually compare how policy gradients behave against actor-critic methods without rewriting glue code.
Key highlights
- 32 projects covering DQN, Double DQN, PPO, DDPG, TD3, SAC, A2C, REINFORCE, and older standbys like hill-climbing and simulated annealing
- Environments span classic control, Box2D, Atari (Pong), PyBullet robotics, and four Udacity nanodegree projects (Navigation, Reacher, Crawler, Tennis)
- Includes a multi-agent MADDPG implementation for the Tennis collaboration-competition task
- FORK (Forward-Looking Actor), a less common model-based hybrid, gets its own explainer
- Every notebook includes training logs; no black-box “it just works” submissions
Caveats
- The README is mostly a directory with Medium-article links for theory; code quality and dependencies are unspecified
- Some environment names are misspelled (“Waker2DBulletEnv,” “HalfChhetahBulletEnv”) which may hint at maintenance gaps
- No stated hardware requirements or training times; reproducing the PyBullet robotics runs could be expensive to discover
Verdict Useful if you’re teaching yourself RL and want to see the same problem attacked six different ways. Less useful if you need a maintained framework with tests and CI—this is a personal curriculum archive, not a library.
Frequently asked
- What is Rafael1s/Deep-Reinforcement-Learning-Algorithms?
- A curated matrix of deep-RL experiments where every cell is a Jupyter notebook with training logs.
- Is Deep-Reinforcement-Learning-Algorithms open source?
- Yes — Rafael1s/Deep-Reinforcement-Learning-Algorithms is an open-source project tracked on heatdrop.
- What language is Deep-Reinforcement-Learning-Algorithms written in?
- Rafael1s/Deep-Reinforcement-Learning-Algorithms is primarily written in Jupyter Notebook.
- How popular is Deep-Reinforcement-Learning-Algorithms?
- Rafael1s/Deep-Reinforcement-Learning-Algorithms has 1k stars on GitHub.
- Where can I find Deep-Reinforcement-Learning-Algorithms?
- Rafael1s/Deep-Reinforcement-Learning-Algorithms is on GitHub at https://github.com/Rafael1s/Deep-Reinforcement-Learning-Algorithms.