PeterGriffinJin/Search-R1
RL training that teaches LLMs when to search and when to think
Search-R1 trains language models to decide for themselves when to reason and when to call a search engine, using standard RL algorithms on open-source infrastructure.
Not currently ranked — collecting fresh signals.
star history
What it does
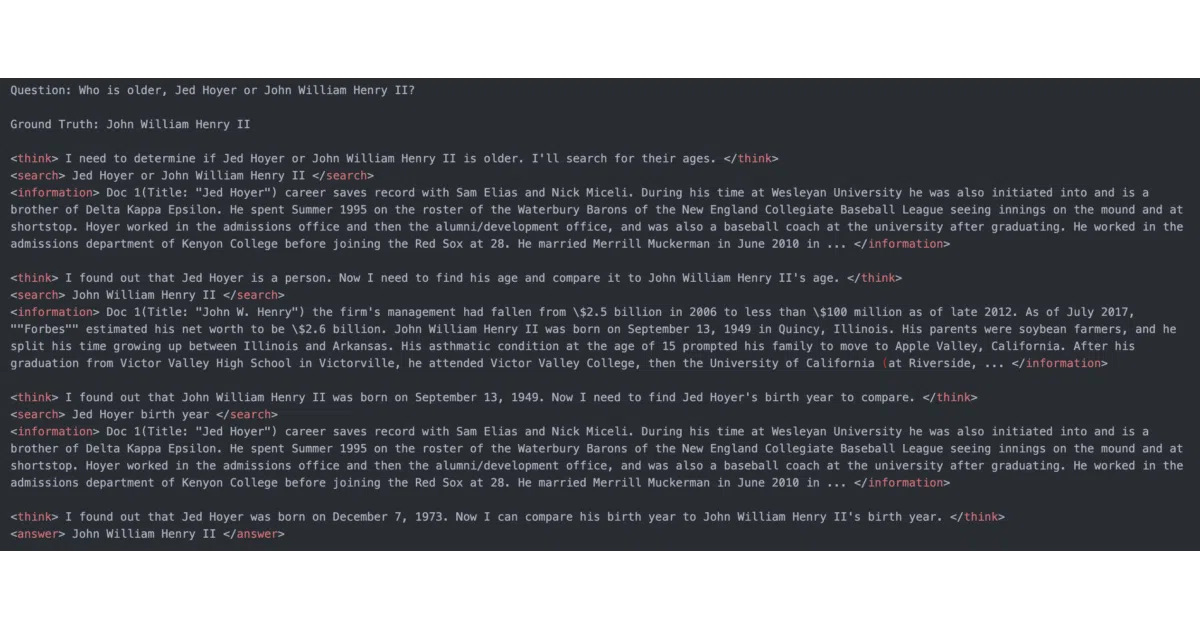
Search-R1 is a reinforcement learning framework—built on veRL—that trains LLMs to interleave chain-of-thought reasoning with search engine calls. It treats retrieval as a tool the model learns to invoke via API during rollouts, using algorithms such as PPO, GRPO, or REINFORCE with rule-based outcome rewards. The search backend runs as a decoupled server, which can be a local sparse or dense retriever, an ANN index, or an online API like Google or Bing.
The interesting bit
The project shows that small base models—specifically 3B-parameter Llama and Qwen—can learn to search and reason from scratch without supervised tool-use data, simply by being rewarded for correct final answers. A 7B model goes further, spontaneously developing multi-turn search trajectories where it issues queries, reads results, and refines its strategy.
Key highlights
- Supports PPO, GRPO, and REINFORCE across models from 3B to 30B+ (multinode)
- Plugs into local retrievers (BM25, FAISS) or commercial search APIs
- Includes neural reranker support and fully open experiment logs
- Two published papers with detailed empirical studies
- Already integrated into veRL upstream and adopted by projects like DeepResearcher
Caveats
- The authors still characterize results as “preliminary,” and the setup requires juggling separate conda environments for training and retrieval.
Verdict
A strong fit for researchers building autonomous reasoning agents who need a trainable, transparent alternative to OpenAI DeepResearch. Skip it if you want a polished end-user product rather than a training pipeline.
Frequently asked
- What is PeterGriffinJin/Search-R1?
- Search-R1 trains language models to decide for themselves when to reason and when to call a search engine, using standard RL algorithms on open-source infrastructure.
- Is Search-R1 open source?
- Yes — PeterGriffinJin/Search-R1 is open source, released under the Apache-2.0 license.
- What language is Search-R1 written in?
- PeterGriffinJin/Search-R1 is primarily written in Python.
- How popular is Search-R1?
- PeterGriffinJin/Search-R1 has 5.1k stars on GitHub.
- Where can I find Search-R1?
- PeterGriffinJin/Search-R1 is on GitHub at https://github.com/PeterGriffinJin/Search-R1.