KaiyangZhou/pytorch-vsumm-reinforce
Teaching agents to make movie trailers without watching movies
A PyTorch reimplementation of an AAAI 2018 paper that frames video summarization as a reinforcement learning problem, rewarding diversity and representativeness instead of ground-truth labels.
Not currently ranked — collecting fresh signals.
star history
What it does
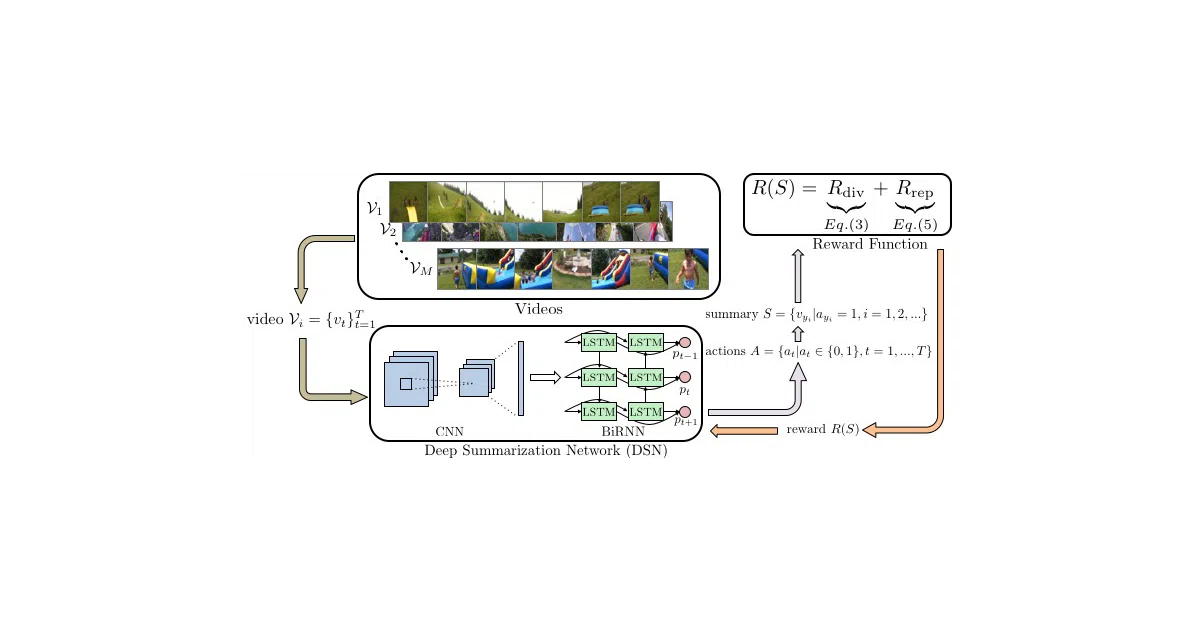
This repo trains a policy network to pick keyframes from videos so the resulting summary is both diverse (not repetitive) and representative (covers the gist). It does this without human annotations — the reward function itself encodes what “good” looks like. The code handles training, evaluation, reward plotting, and even stitching selected frames back into a watchable .mp4.
The interesting bit
The unsupervised angle is the hook: no labeled summaries needed. The agent learns purely from a hand-designed reward that penalizes redundancy and rewards coverage. It’s a neat inversion of the usual supervised setup where you’d need humans to score thousands of clips.
Key highlights
- PyTorch port of the original Theano implementation, targeting PyTorch 0.4.0 and Python 2.7
- Preprocessed datasets available (173.5MB, now mirrored to Google Drive after the QMUL server went down)
- Built-in visualization: reward curves per epoch, per-video, and score-vs-ground-truth comparisons
summary2video.pyconverts binary frame selections into actual summary videos with controllable FPS- Supports custom data: extract image features to HDF5, define splits, and train
Caveats
- Stuck on PyTorch 0.4.0 and Python 2.7; expect dependency archaeology if you’re on modern stacks
- The README notes you may need to manually install
tabulateandh5py, and “other missing dependencies” — the dependency list is implicit rather than explicit - Frame naming conventions in
summary2video.pyrequire manual editing on line 22
Verdict
Worth a look if you’re researching video summarization or exploring how reward engineering can replace labels in structured prediction. Skip it if you need production-ready code on current PyTorch; this is a research artifact with the expected rough edges.
Frequently asked
- What is KaiyangZhou/pytorch-vsumm-reinforce?
- A PyTorch reimplementation of an AAAI 2018 paper that frames video summarization as a reinforcement learning problem, rewarding diversity and representativeness instead of ground-truth labels.
- Is pytorch-vsumm-reinforce open source?
- Yes — KaiyangZhou/pytorch-vsumm-reinforce is open source, released under the MIT license.
- What language is pytorch-vsumm-reinforce written in?
- KaiyangZhou/pytorch-vsumm-reinforce is primarily written in Python.
- How popular is pytorch-vsumm-reinforce?
- KaiyangZhou/pytorch-vsumm-reinforce has 505 stars on GitHub.
- Where can I find pytorch-vsumm-reinforce?
- KaiyangZhou/pytorch-vsumm-reinforce is on GitHub at https://github.com/KaiyangZhou/pytorch-vsumm-reinforce.