Dicklesworthstone/swiss_army_llama
FastAPI wrapper that turns local LLMs into an embedding and search utility belt
A single service that embeds text, audio, and documents via llama.cpp, caches results in SQLite, and offers statistical similarity measures most vector databases skip.
Not currently ranked — collecting fresh signals.
star history
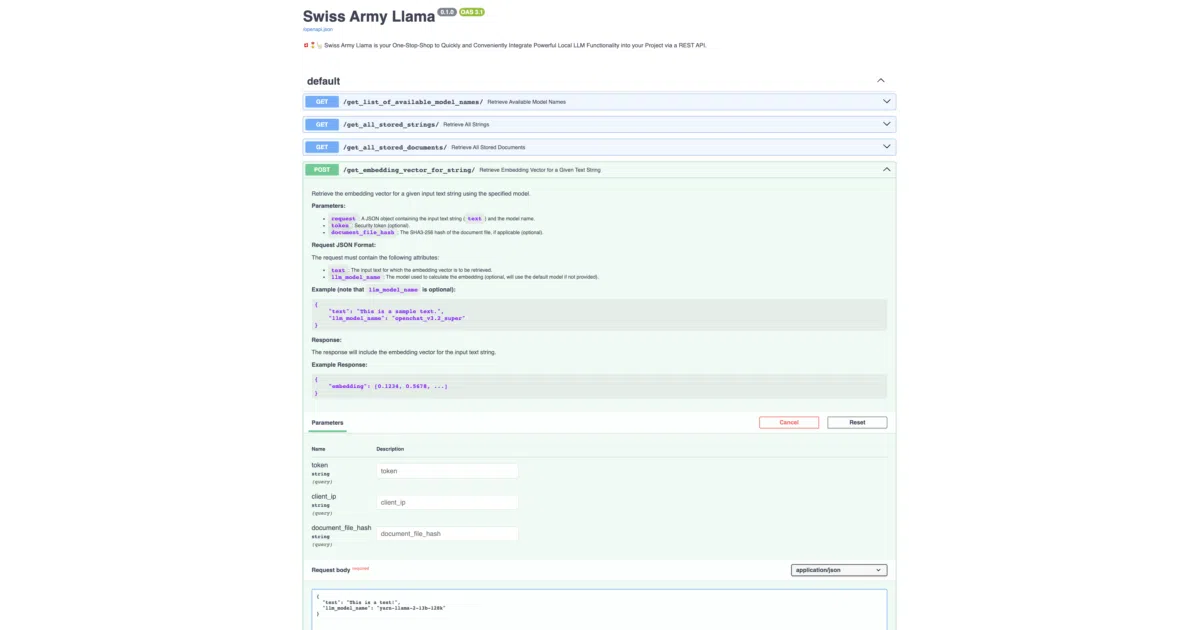
What it does Swiss Army Llama is a FastAPI service that exposes REST endpoints for computing text embeddings with local models through llama.cpp, generating completions, and running semantic search. It ingests plaintext, PDFs, Word files, images (with OCR via Tesseract), and even MP3/WAV audio (transcribed via Whisper), then caches every embedding in SQLite to avoid redundant computation.
The interesting bit
The project layers a Rust-backed library, fast_vector_similarity, on top of the usual cosine-similarity vector search. FAISS handles the coarse filtering, then the service can re-rank candidates with statistical measures like Spearman’s rho, Kendall’s tau, and Hoeffding’s D—dependency metrics you rarely see outside R notebooks. It also offers seven embedding pooling strategies, from mean pooling to SVD and ICA, for squeezing variable-length texts into fixed vectors.
Key highlights
- Ingests and embeds documents, scanned images, and audio through a single API
- Two-stage semantic search: FAISS cosine pre-filter, then advanced statistical similarity re-ranking
- Optional RAM disk management for faster model loading
- Redis-backed request locking to support parallel uvicorn workers
- Built-in browser log viewer for monitoring without SSH access
- Returns results as JSON or ZIP; includes Swagger UI for interactive testing
Caveats
- Setup is Ubuntu-centric and pulls in a long list of system dependencies (Tesseract, antiword, poppler, ffmpeg, etc.)
- The README warns against running setup scripts with sudo on your own machine and suggests a VPS instead
- Configuration details in the README are truncated mid-sentence, so some env vars are unclear
Verdict Worth a look if you need a self-hosted embedding pipeline with more statistical rigor than a standard vector DB, or if you want to expose llama.cpp and Whisper through a uniform REST API. Skip it if you already have a managed embedding service and don’t need exotic similarity measures or local audio transcription.
Frequently asked
- What is Dicklesworthstone/swiss_army_llama?
- A single service that embeds text, audio, and documents via llama.cpp, caches results in SQLite, and offers statistical similarity measures most vector databases skip.
- Is swiss_army_llama open source?
- Yes — Dicklesworthstone/swiss_army_llama is an open-source project tracked on heatdrop.
- What language is swiss_army_llama written in?
- Dicklesworthstone/swiss_army_llama is primarily written in Python.
- How popular is swiss_army_llama?
- Dicklesworthstone/swiss_army_llama has 1.1k stars on GitHub.
- Where can I find swiss_army_llama?
- Dicklesworthstone/swiss_army_llama is on GitHub at https://github.com/Dicklesworthstone/swiss_army_llama.