01
lkuza2/java-speech-api
+0.1 ★/day→steady
A wrapper around Google's speech services that handles the tedious audio plumbing so you don't have to.
A wrapper around Google's speech services that handles the tedious audio plumbing so you don't have to.
A single repo that lets you train DCGAN, VAE, or DRAW without wrestling three different codebases.
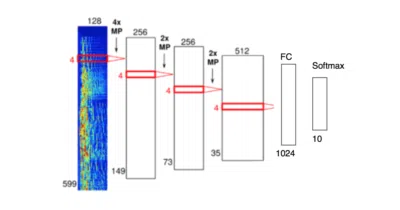
A 2016 Tel Aviv University project that swaps Tao Feng's RBM for a TensorFlow CNN and scrapes 30-second previews to classify ten music genres.
A dead-simple TensorFlow implementation that trades bleeding-edge complexity for actual comprehension.
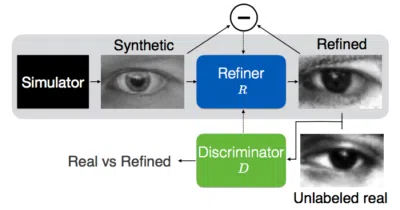
A 2017-era implementation that uses adversarial training to refine synthetic eye images so they fool a discriminator without losing their gaze labels.
A straightforward notebook implementation of Wasserstein GAN that lets you flip the loss signs and still trains, because duality is weird like that.
A 2016 paper implementation that generates flower images from text descriptions, built when TensorFlow 1.x was fresh and "skip thought vectors" sounded futuristic.
A 2017 ICCV paper that synthesizes frontal faces from extreme side angles using two perceptual paths at once.
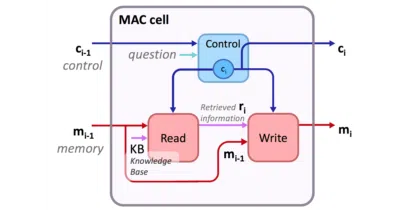
Stanford's MAC cell breaks visual reasoning into explicit, inspectable computation steps—rare honesty in a field that usually hides its work.
Sonus gives Node.js projects offline hotword detection, then streams speech to cloud STT only after you get its attention.
A Python shim around Ce Liu's venerable C++ Coarse2Fine optical flow, minus the OpenCV dependency headache.
A clean TensorFlow implementation of Alex Graves' 2013 paper that generates plausible cursive from text, complete with attention windows and style knobs.
A TensorFlow implementation of extreme learned image compression that trades exact reconstruction for tiny file sizes by letting a generator dream up the textures.
Before Hugging Face and Lightning, there was this: one developer's clean re-implementation of the papers that defined an era.
MoCoGAN disentangles motion and content in video generation, letting you swap faces while keeping the expression—or vice versa.
A Keras project that generates new dance sequences by compressing video frames into a latent space, then predicting the next pose with an LSTM and Mixture Density Network.
Parrots wraps ASR and TTS into pip-installable Python with pre-trained voices and emotional fine-tuning.
A 2018 CVPR spotlight paper that uses attention maps to stop generative networks from inventing plausible-looking but wrong background details behind raindrops.
A Torch7 implementation that generates short, plausible video clips by separating foreground motion from static backgrounds using adversarial training.
VOSK skips neural network training in favor of storing every audio chunk it has ever seen, then fingerprint-matches new input against the hoard.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.