01
lidge-jun/opencodex
+88% /wk +630 ★/day↗accelerating
It breaks the vendor lock on Codex and Claude Code by translating their API calls to any LLM backend you choose.
It breaks the vendor lock on Codex and Claude Code by translating their API calls to any LLM backend you choose.
A demo repo for running extreme-quantized language models locally without needing a research cluster.
An unofficial proxy that borrows your ChatGPT/Codex OAuth tokens to serve a local OpenAI-compatible API, bypassing API credit billing.
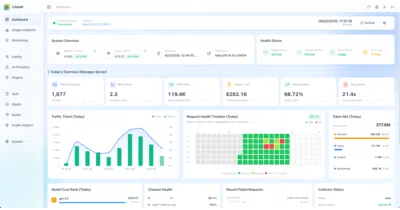
It exists to stop your AI gateway from quietly burning through quotas, cash, and expired OAuth tokens without leaving a paper trail.
It keeps the entire agent loop—prompts, tool calls, browser state, and memory—on your laptop so you don't have to rent a control plane in the cloud.
A Go proxy that tricks Claude Code into using $5/month open models through OpenCode instead of Anthropic's API.
Espressif's C framework turns cheap microcontrollers into edge AI agents you program through IM chat.
One desktop UI that wires together ComfyUI, OpenAI, Gemini, ModelScope, and a dozen other generative APIs—plus some very opinionated legal terms.
turbovec exists so you can index embeddings immediately—no training, no tuning, no rebuilds—and search them faster than FAISS in a fraction of the RAM.
WorldX turns one sentence into a self-running simulation of AI agents who gossip, scheme, and remember grudges without a script.
A Bittensor subnet that uses zero-knowledge proofs to verify miners actually ran the AI models they claim to.
AngelSlim integrates quantization, speculative decoding, and distillation so you can shrink and serve massive models from a single toolkit.
It turns your local machine into an OpenAI-compatible inference endpoint so agents and IDEs can run on offline models without reconfiguration.
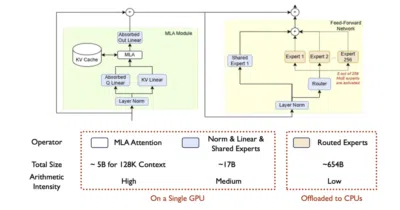
KTransformers makes CPU-GPU heterogeneous inference and fine-tuning for massive MoE models almost practical on consumer hardware.
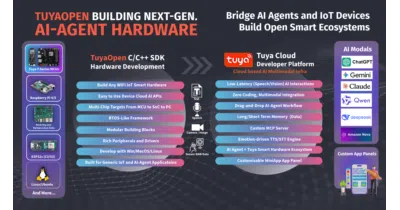
A C/C++ SDK that bundles speech recognition, multimodal AI, and cloud LLM plumbing so Wi-Fi modules and MCUs can behave like smart agents.
It wraps open-source image-to-3D models in a desktop app so your snapshots never leave your GPU.
It exists because cloud image generators deserve a local memory layer, a branching canvas, and a UI outside the chat thread.
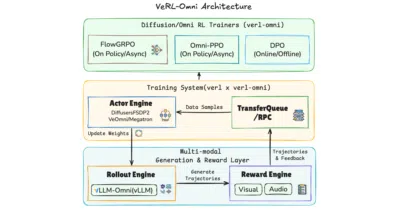
It split off from `verl` to give diffusion, video, and omni-modality models an RL post-training framework that doesn't treat them like chatbots.
Bytez wraps 175,000+ AI models behind a single endpoint so you don't have to host them yourself.
Google's edge ML runtime grows up, adds async NPU support, and finally admits PyTorch exists.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.