zhanlaoban/EDA_NLP_for_Chinese
Four cheap tricks to stretch your Chinese NLP dataset
A port of the EDA paper that swaps, deletes, and jumbles Chinese text to fake more training data.
Not currently ranked — collecting fresh signals.
star history
What it does Takes a tab-separated Chinese text file and spits out augmented copies using four simple mutations: synonym replacement, random insertion, random swap, and random deletion. It is a direct adaptation of the English EDA toolkit, wired for Chinese tokenization via jieba and synonym lookup via the Synonyms library.
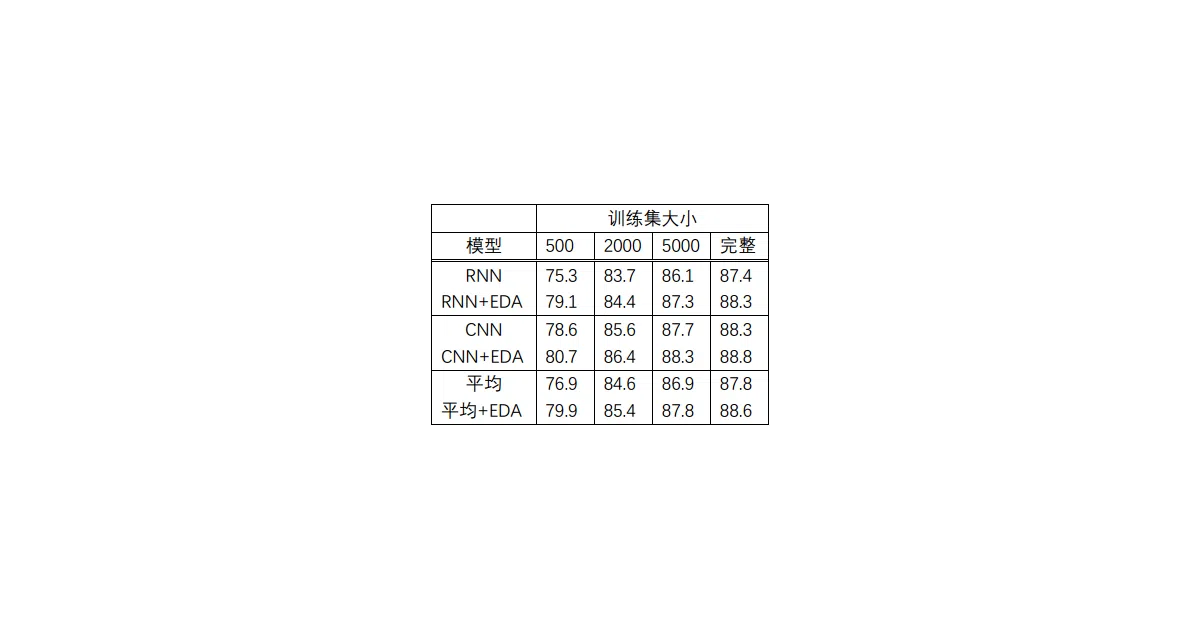
The interesting bit The README doubles as a surprisingly thorough paper reading note, complete with LaTeX formulas and experimental tables. The author did not just translate the code; they translated the paper’s reasoning into Chinese, including the warning that too much augmentation can corrupt labels.
Key highlights
- Four augmentation strategies: synonym replacement, random insertion, random swap, random deletion
- Sentence-length-aware mutation counts via an
alphascaling factor - Bundles four common Chinese stopword lists (cn, HIT, Baidu, SCU)
- CLI interface:
python code/augment.py --input=train.txt --output=train_augmented.txt --num_aug=16 --alpha=0.05 - Paper notes claim EDA can match full-dataset accuracy with only 50% of the data on small classification tasks
Caveats
- The code itself is not shown in the README; you are trusting that
augment.pyexists and matches the described behavior - Synonym quality depends on the bundled Synonyms library, which is not discussed in detail
- The paper’s reported gains (0.8% on full data, 3% on 500-sample sets) are from English benchmarks, not Chinese ones
Verdict Worth a look if you are building Chinese text classifiers with thin training data and want a quick augmentation baseline before trying heavier artillery like back-translation or LLM-based generation. Skip it if you need guarantees that label semantics survive the noise.
Frequently asked
- What is zhanlaoban/EDA_NLP_for_Chinese?
- A port of the EDA paper that swaps, deletes, and jumbles Chinese text to fake more training data.
- Is EDA_NLP_for_Chinese open source?
- Yes — zhanlaoban/EDA_NLP_for_Chinese is an open-source project tracked on heatdrop.
- What language is EDA_NLP_for_Chinese written in?
- zhanlaoban/EDA_NLP_for_Chinese is primarily written in Python.
- How popular is EDA_NLP_for_Chinese?
- zhanlaoban/EDA_NLP_for_Chinese has 1.4k stars on GitHub.
- Where can I find EDA_NLP_for_Chinese?
- zhanlaoban/EDA_NLP_for_Chinese is on GitHub at https://github.com/zhanlaoban/EDA_NLP_for_Chinese.