z-lab/dflash
Block diffusion meets speculative decoding
DFlash speeds up LLM inference by using a tiny block-diffusion model to draft tokens in parallel for speculative decoding.
Velocity · 7d
+5.1
★ / day
Trend
↘cooling
star history
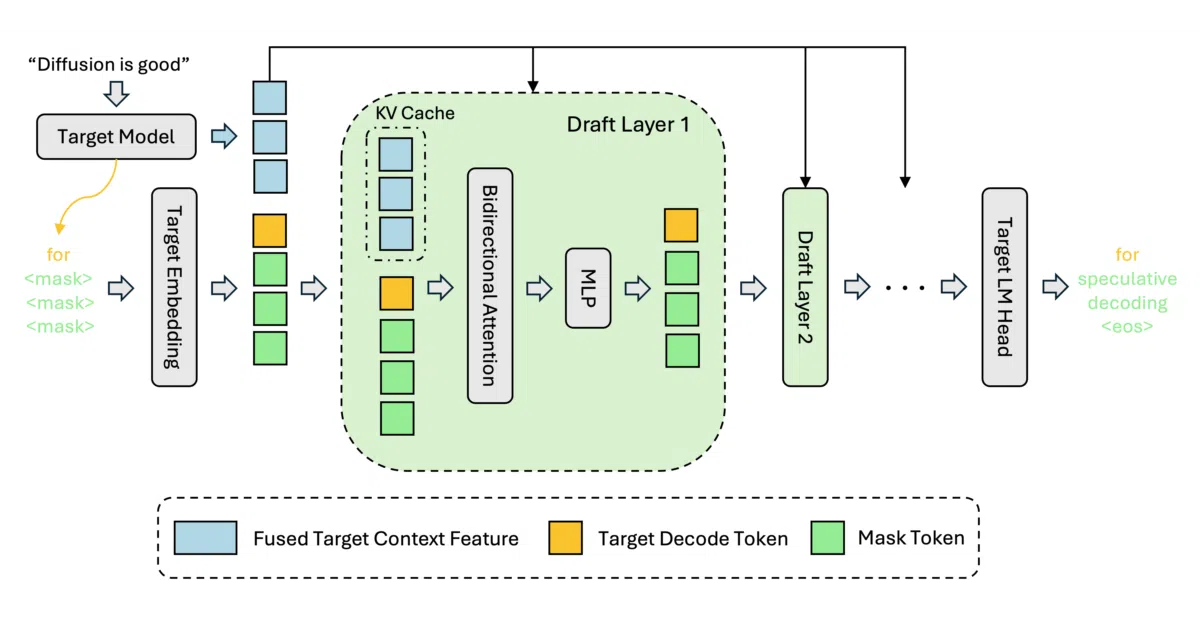
What it does DFlash is a lightweight block diffusion model that acts as a draft engine for speculative decoding. Instead of generating tokens one by one, it predicts blocks of tokens in parallel, which a larger target LLM then verifies. It plugs into existing serving stacks—vLLM, SGLang, Transformers, and MLX—so you can speed up inference for supported models without replacing your target weights.
The interesting bit Most speculative decoders use a smaller autoregressive model to guess the next few tokens; DFlash uses diffusion, which is naturally parallel across a block. The README pitches efficiency and quality but keeps the actual speedup numbers implicit—leaving you to run the bundled benchmarks to see the gain.
Key highlights
- Supports a wide range of target models, including Gemma-4, Qwen3.5/3.6, Kimi, MiniMax, GPT-OSS, and Llama-3.1, with draft weights hosted on HuggingFace.
- Integrates with four inference backends: vLLM, SGLang, HuggingFace Transformers, and MLX for Apple Silicon.
- Ships with unified benchmarking scripts across GSM8K, MATH-500, HumanEval, MBPP, and MT-Bench.
- Training recipe will be open-sourced soon, allowing custom draft models for other LLMs.
Caveats
- The Transformers backend only supports Qwen3 and Llama-3.1 models; everything else needs vLLM, SGLang, or MLX.
- Gemma-4 support in vLLM currently requires a temporary custom build rather than the standard release.
- Several integrations, including some model ports and SGLang’s schedule overlapping, are marked experimental or preview.
Verdict Worth a look if you run inference for supported models and want to cut latency without distilling your main model. Skip it if your model isn’t on the list and you can’t wait for the promised training recipe.
Frequently asked
- What is z-lab/dflash?
- DFlash speeds up LLM inference by using a tiny block-diffusion model to draft tokens in parallel for speculative decoding.
- Is dflash open source?
- Yes — z-lab/dflash is open source, released under the MIT license.
- What language is dflash written in?
- z-lab/dflash is primarily written in Python.
- How popular is dflash?
- z-lab/dflash has 5.5k stars on GitHub and is currently cooling off.
- Where can I find dflash?
- z-lab/dflash is on GitHub at https://github.com/z-lab/dflash.