yuanxiaosc/Entity-Relation-Extraction
A 2019 Chinese NLP competition solution that still pipelines along
A TensorFlow/BERT pipeline for schema-constrained entity and relation extraction, built for a 2019 Baidu competition and left as a reproducible artifact.
Not currently ranked — collecting fresh signals.
star history
What it does
This is a two-stage pipeline for extracting subject-predicate-object triples from Chinese text. First, a multi-label BERT classifier guesses which relations a sentence might contain. Then a sequence-labeling BERT model finds the actual entity spans for those relations. The output is structured triples like (entity1, relation, entity2) that must obey a predefined schema — e.g., only a “图书作品” can be the subject of an “作者” relation.
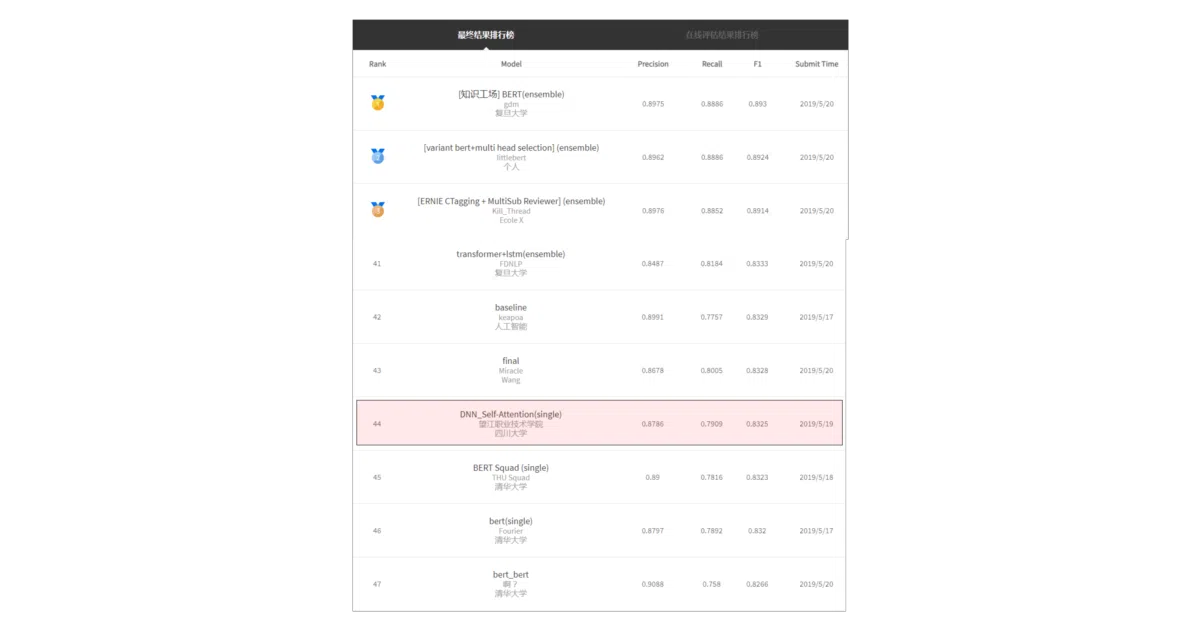
The interesting bit The pipeline mirrors the architecture used by the winning team in the 2019 competition (89.3% F1), yet the README is admirably blunt about its own limits: training can be parallel, but inference must be strictly sequential. The schema constraint is the real task master — the model isn’t free-associating relations, it’s slot-filling against 50 predefined templates.
Key highlights
- Built on TensorFlow 1.12+ and Chinese BERT-base, with the usual BERT hyperparameters (2e-5 LR, 128 seq length)
- Targets the SKE dataset: 430K triples, 210K sentences, 50 schemas drawn from Baidu Baike and feed text
- Published results top out around 79.7% F1 — solid but not championship-grade
- Includes data prep scripts, evaluation utilities, and a direct link to the winning team’s report for comparison
- README is bilingual and notably honest about data availability (“There is no longer a raw data download”)
Caveats
- Requires TensorFlow 1.x, which is now firmly in maintenance territory
- Raw competition data is no longer officially available; contact the author directly if you want to reproduce
- Inference is explicitly sequential, not end-to-end — you run classification, convert outputs, then run labeling
Verdict Worth studying if you’re building schema-constrained Chinese IE systems or need a concrete BERT pipeline reference from the pre-transformers-as-platforms era. Skip it if you need modern PyTorch, multilingual support, or an actively maintained codebase.
Frequently asked
- What is yuanxiaosc/Entity-Relation-Extraction?
- A TensorFlow/BERT pipeline for schema-constrained entity and relation extraction, built for a 2019 Baidu competition and left as a reproducible artifact.
- Is Entity-Relation-Extraction open source?
- Yes — yuanxiaosc/Entity-Relation-Extraction is an open-source project tracked on heatdrop.
- What language is Entity-Relation-Extraction written in?
- yuanxiaosc/Entity-Relation-Extraction is primarily written in Python.
- How popular is Entity-Relation-Extraction?
- yuanxiaosc/Entity-Relation-Extraction has 1.2k stars on GitHub.
- Where can I find Entity-Relation-Extraction?
- yuanxiaosc/Entity-Relation-Extraction is on GitHub at https://github.com/yuanxiaosc/Entity-Relation-Extraction.