yrlu/irl-imitation
Teaching robots by watching: three ways to guess the reward
A clean reference implementation of classic inverse reinforcement learning algorithms, frozen in 2017 dependencies.
Not currently ranked — collecting fresh signals.
star history
What it does
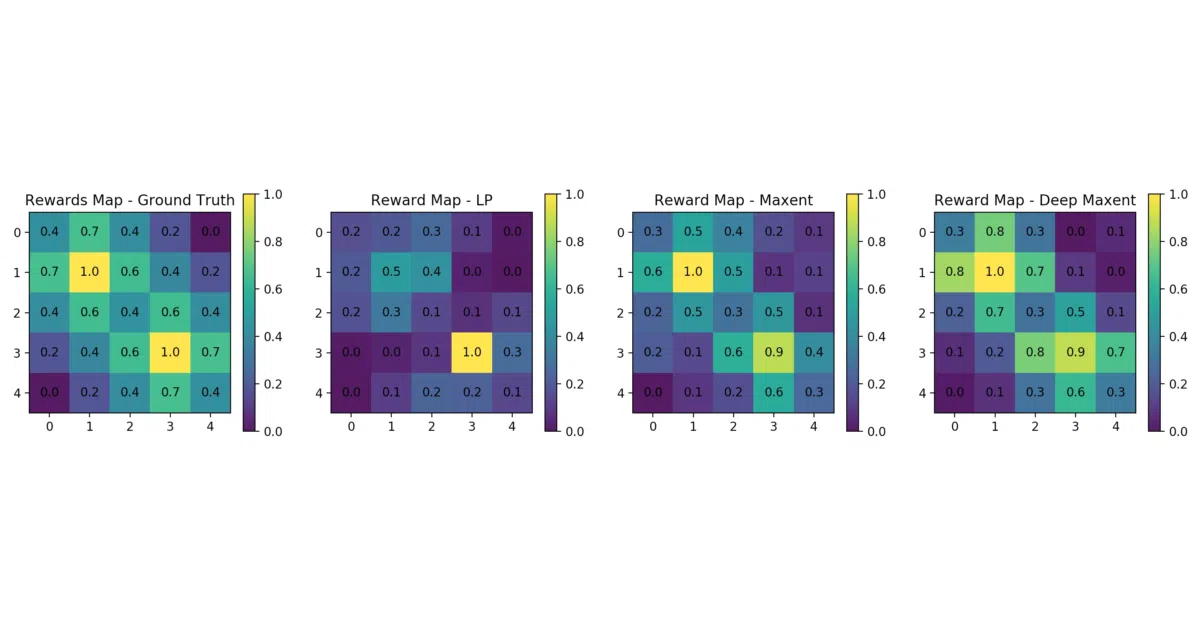
This repo implements three foundational IRL algorithms that infer an agent’s reward function from observed behavior. You get linear IRL (Ng & Russell 2000), maximum entropy IRL (Ziebart et al. 2008), and a deep neural variant (Wulfmeier et al. 2015), all running on toy 1D/2D gridworlds with value iteration as the MDP solver. Run demo.py and watch the reward maps reconstruct.
The interesting bit
The deep MaxEnt implementation doesn’t follow the paper exactly — the author tweaked it with ELU activations, gradient clipping, and L2 regularization, which is the kind of honest footnote you rarely see. The maxent implementation also credits Matthew Alger’s prior work openly rather than pretending to have reinvented the wheel.
Key highlights
- Three algorithms spanning 15 years of IRL research in one codebase
- Visual reward-map outputs make the abstract concrete
- Includes DOI and proper BibTeX for academic use
demo.pyactually runs out of the box (a low bar, but many repos fail it)
Caveats
- Python 2.7 and TensorFlow 0.12.1 — this is archaeological software at this point
- Only gridworlds; no continuous control or Atari hooks
- Deep MaxEnt is explicitly “not exactly the model proposed in the paper”
Verdict
Grab this if you need to understand or teach the classics, or want a baseline to beat. Skip it if you need something production-ready; the dependency stack alone will eat your afternoon.
Frequently asked
- What is yrlu/irl-imitation?
- A clean reference implementation of classic inverse reinforcement learning algorithms, frozen in 2017 dependencies.
- Is irl-imitation open source?
- Yes — yrlu/irl-imitation is an open-source project tracked on heatdrop.
- What language is irl-imitation written in?
- yrlu/irl-imitation is primarily written in Python.
- How popular is irl-imitation?
- yrlu/irl-imitation has 678 stars on GitHub.
- Where can I find irl-imitation?
- yrlu/irl-imitation is on GitHub at https://github.com/yrlu/irl-imitation.