ypwhs/dogs_vs_cats
Kaggle Cat-Dog War: Ensemble Three Giants, Skip the GPU Burn
A 2017-era Keras notebook that extracts frozen features from ResNet50, Xception and InceptionV3, then trains a lightweight classifier in seconds on a laptop.
Not currently ranked — collecting fresh signals.
star history
What it does
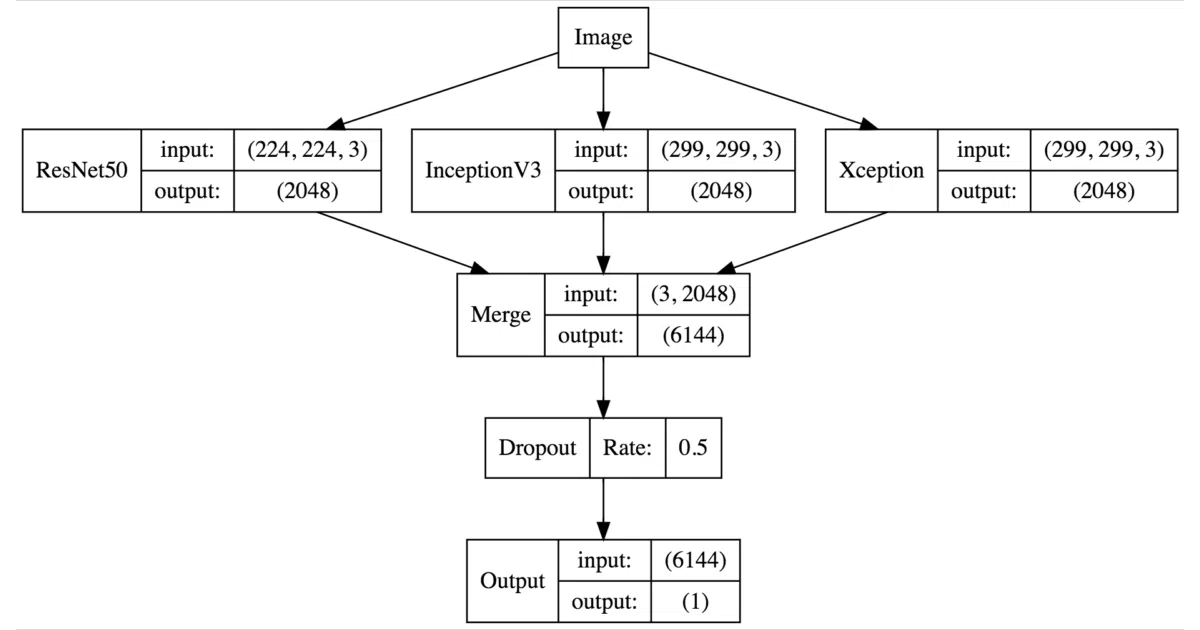
This is a walkthrough for the classic Kaggle “Dogs vs. Cats” competition. It takes 25,000 labeled training images, shuffles them into class folders via symbolic links (no duplicate disk space), then runs three pre-trained ImageNet models as fixed feature extractors. The resulting 6,144-dimensional vectors get fed into a single dropout layer and a sigmoid output. Validation accuracy lands at 99.6%.
The interesting bit
The author treats heavy CNNs as one-off compilers: extract once, save to HDF5, then train downstream on a CPU in under ten seconds per epoch. It’s a pragmatic hack from the Keras 1.2 era, complete with a clipped LogLoss trick (0.005–0.995) to dodge Kaggle’s penalty for overconfident wrong answers.
Key highlights
- Pre-trains on ResNet50, InceptionV3 and Xception, concatenating their gap (GlobalAveragePooling) outputs
- Symbolic-link preprocessing avoids copying 25,000 images
- Full training of the top classifier runs in ~1 second per epoch after feature extraction
- Kaggle submission score of 0.04141, reportedly ranking 20th out of 1,314 at the time
- Includes a neat Graphviz model diagram showing the three-tower merge
Caveats
- Locked to Keras 1.2.2; newer versions will need syntax tweaks (e.g.,
nb_sample→samples,nb_epoch→epochs) - No fine-tuning or data augmentation shown, and the README notes these as obvious next steps
- Feature extraction still needs a GPU or cloud instance (10–20 min per model on AWS p2.xlarge)
Verdict
Worth a skim if you’re teaching transfer learning or need a dead-simple ensemble baseline. Skip it if you want modern PyTorch, end-to-end fine-tuning, or a production pipeline—this is a 2017 tutorial frozen in amber.
Frequently asked
- What is ypwhs/dogs_vs_cats?
- A 2017-era Keras notebook that extracts frozen features from ResNet50, Xception and InceptionV3, then trains a lightweight classifier in seconds on a laptop.
- Is dogs_vs_cats open source?
- Yes — ypwhs/dogs_vs_cats is an open-source project tracked on heatdrop.
- What language is dogs_vs_cats written in?
- ypwhs/dogs_vs_cats is primarily written in Jupyter Notebook.
- How popular is dogs_vs_cats?
- ypwhs/dogs_vs_cats has 637 stars on GitHub.
- Where can I find dogs_vs_cats?
- ypwhs/dogs_vs_cats is on GitHub at https://github.com/ypwhs/dogs_vs_cats.