xxxnell/how-do-vits-work
Why Vision Transformers work: spatial smoothing, not magic
This repo implements an ICLR 2022 Spotlight paper showing that Vision Transformers work because self-attention acts as a trainable spatial blur rather than a long-range dependency model, and derives hybrid CNN-Transformer architectures that outperform pure CNNs on small data.
Not currently ranked — collecting fresh signals.
star history
What it does
The repository hosts the official PyTorch implementation of the ICLR 2022 Spotlight paper How Do Vision Transformers Work?. It bundles training and evaluation code for a zoo of models—ResNet, ViT, Swin, PiT, MLP-Mixer, and the paper’s own AlterNet—plus notebooks to reproduce loss-landscape and Fourier analyses. The authors use this tooling to argue that multi-head self-attention (MSA) improves vision models by flattening loss landscapes and acting as a data-specific spatial smoother, not by capturing long-range dependencies.
The interesting bit
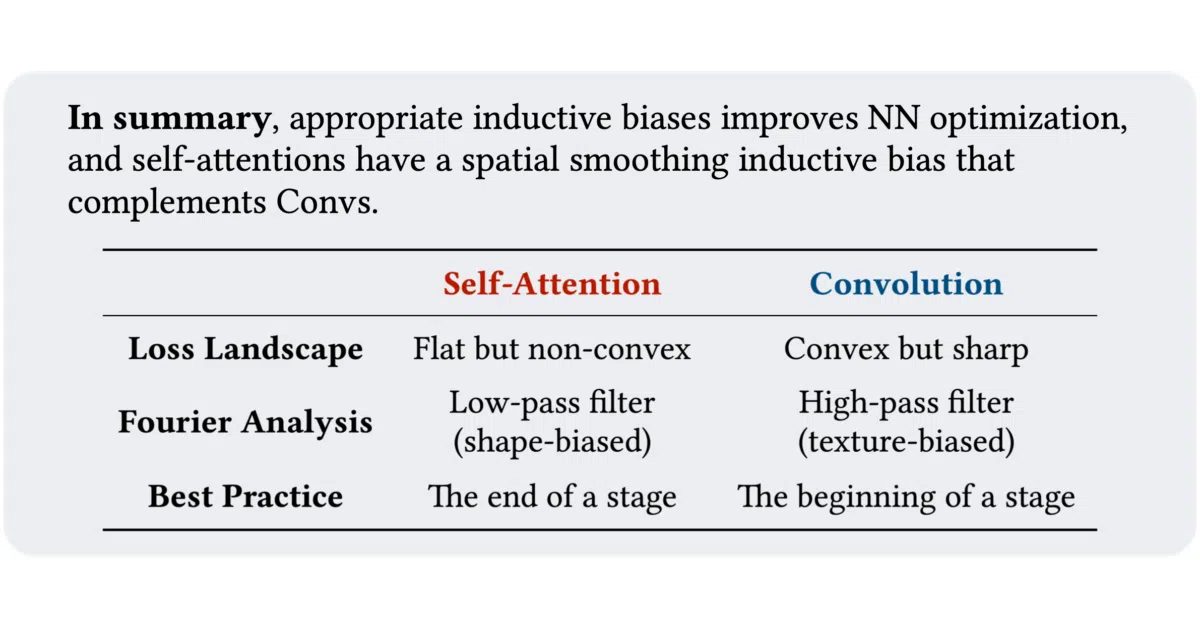
The paper’s central heresy is that self-attention is not a generalized convolution, but a trainable, importance-weighted blur filter that complements CNNs: MSAs behave as low-pass, shape-biased filters while convolutions behave as high-pass, texture-biased filters. This leads to AlterNet, a hybrid that parks MSA blocks only at the end of each stage, outperforming pure CNNs on both ImageNet-scale and small CIFAR regimes where vanilla ViTs typically collapse.
Key highlights
- Claims MSA success comes from flattening loss landscapes (reducing Hessian eigenvalue magnitudes) via data specificity, not long-range dependencies.
- Frames MSAs as low-pass filters and convolutions as high-pass filters, suggesting the two are complementary rather than interchangeable.
- Proposes AlterNet, a hybrid architecture that replaces stage-final conv blocks with MSAs to improve accuracy on large and small datasets alike.
- Ships with pretrained CIFAR-100 checkpoints and Jupyter notebooks for classification, Fourier analysis, and loss-landscape visualization.
- Includes uncertainty and calibration metrics—ECE, NLL, reliability diagrams—alongside standard accuracy measures.
Caveats
- The README reads like a paper précis with code snippets appended; deep code-level documentation is largely left to the notebooks.
- Pretrained weights are only provided for CIFAR-100, with ImageNet experiments relying on external
timmmodels.
Verdict
A solid stop if you are studying ViT mechanics, loss-landscape geometry, or hybrid CNN-Transformer design; otherwise, if you just need a battle-tested model zoo, timm already has you covered.
Frequently asked
- What is xxxnell/how-do-vits-work?
- This repo implements an ICLR 2022 Spotlight paper showing that Vision Transformers work because self-attention acts as a trainable spatial blur rather than a long-range dependency model, and derives hybrid CNN-Transformer architectures that outperform pure CNNs on small data.
- Is how-do-vits-work open source?
- Yes — xxxnell/how-do-vits-work is open source, released under the Apache-2.0 license.
- What language is how-do-vits-work written in?
- xxxnell/how-do-vits-work is primarily written in Python.
- How popular is how-do-vits-work?
- xxxnell/how-do-vits-work has 822 stars on GitHub.
- Where can I find how-do-vits-work?
- xxxnell/how-do-vits-work is on GitHub at https://github.com/xxxnell/how-do-vits-work.