xorq-labs/xorq
Git-native memory for agents that keep rewriting your pandas scripts
Xorq turns ephemeral agent work into durable, executable pipelines that survive across sessions, machines, and agents.
Not currently ranked — collecting fresh signals.
star history
What it does
Xorq is a system for packaging tabular data pipelines into reproducible, content-addressed artifacts stored in git. It wraps Ibis expressions with caching, multi-engine execution, and environment pinning via uv, then catalogs them so agents or humans can discover and rerun them without reconstructing context from chat history.
The interesting bit
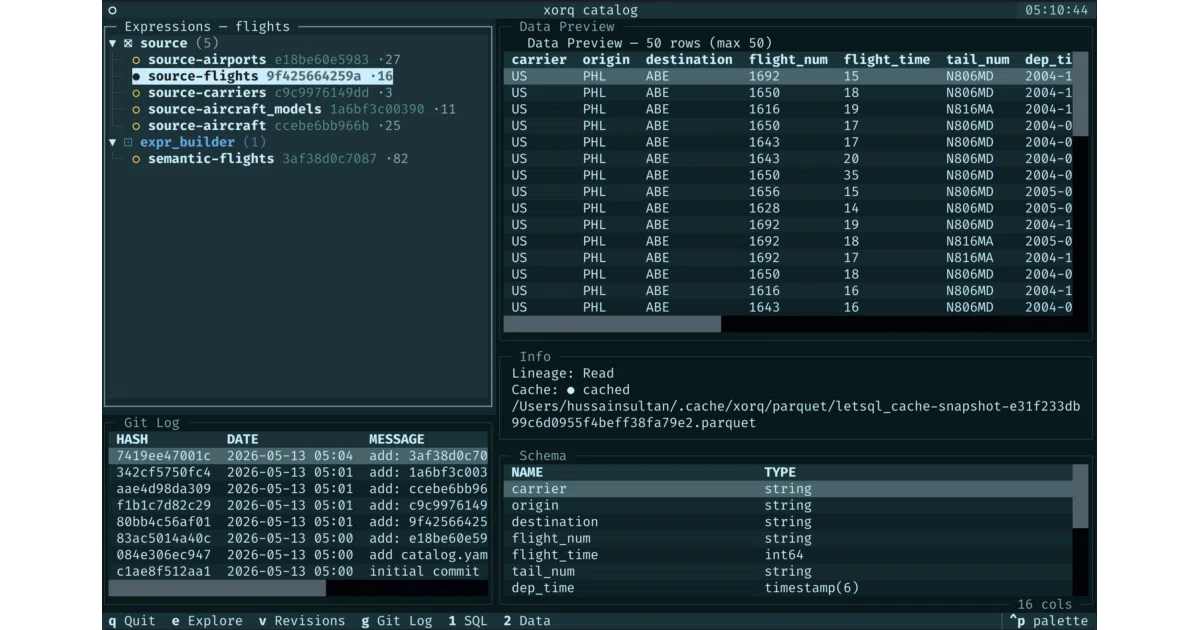
The catalog is literally a git repo: aliases as symlinks, entries as zipped builds, metadata as grep-able YAML sidecars. No API to learn, no service to run — an agent that clones the repo can list, filter, and execute pipelines with standard file operations. The authors compare it to “Unix pipes text streams between small programs; Xorq pipes Arrow streams between expressions.”
Key highlights
- Declarative Ibis expressions compile to DataFusion, DuckDB, SQLite, pandas, Snowflake, Databricks, Trino, Postgres, or PyIceberg
- Each entry ships with
expr.yamlmanifest, pinnedrequirements.txt, and built wheel for reproducible execution - CLI for agents (
xorq init,xorq catalog add,xorq run) plus TUI for humans to browse schema, lineage, and git history - Claude Code plugin with four slash commands for building catalogs agent-side
- Sklearn pipelines translatable to deferred expressions via
Pipeline.from_instance()
Caveats
- 511 stars; young project with evolving API (version 0.3.24 in examples)
- Benchmark claim (Haiku 50% → 84% on DABStep) is specific to semantic catalog context injection, not general pipeline execution
- README is thorough but documentation links suggest some features still need external reference
Verdict
Worth a look if you’re wrangling agent-generated data scripts and tired of losing work between sessions. Probably overkill if your pipelines already live in dbt or you don’t need cross-agent portability.
Frequently asked
- What is xorq-labs/xorq?
- Xorq turns ephemeral agent work into durable, executable pipelines that survive across sessions, machines, and agents.
- Is xorq open source?
- Yes — xorq-labs/xorq is open source, released under the Apache-2.0 license.
- What language is xorq written in?
- xorq-labs/xorq is primarily written in Python.
- How popular is xorq?
- xorq-labs/xorq has 538 stars on GitHub.
- Where can I find xorq?
- xorq-labs/xorq is on GitHub at https://github.com/xorq-labs/xorq.