wendy7756/AI-Video-Transcriber
Transcribe Videos by Snagging Subtitles Before Booting Whisper
It transcribes and summarizes videos by extracting existing subtitles before ever touching Whisper, then hands the text to any OpenAI-compatible LLM you configure.
Velocity · 7d
+3.9
★ / day
Trend
↗accelerating
star history
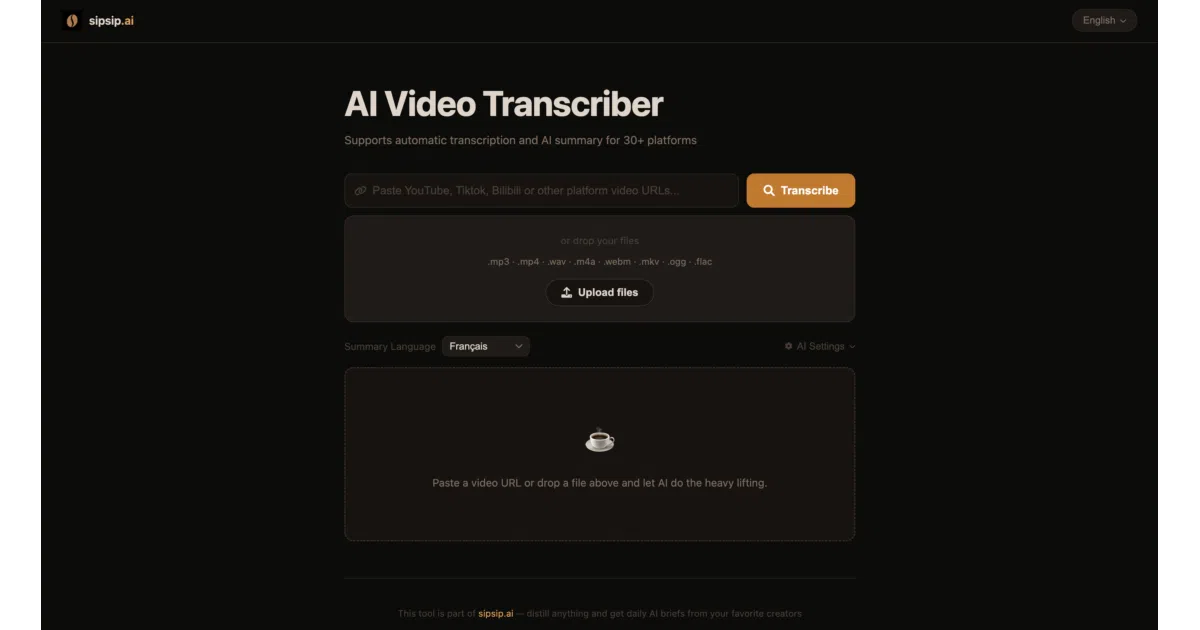
What it does AI Video Transcriber is a self-hosted web app that ingests video or podcast URLs from roughly 30 platforms—YouTube, TikTok, Bilibili, and others—or local audio, video, and plain-text files. It extracts or transcribes speech into text, runs the result through an LLM for cleanup and summarization, and can translate the output into another language if requested. The whole thing is packaged as a FastAPI backend with a vanilla JavaScript frontend, runnable via Docker or a local Python environment.
The interesting bit The backend checks for native platform subtitles first—YouTube captions, for instance—and pulls them instantly without downloading or processing audio. Only when no subtitles exist does it fall back to Faster-Whisper, which keeps GPU cycles and wait times low. You also plug in your own OpenAI-compatible API endpoint directly through the UI, and the app auto-discovers available models rather than hardcoding a vendor list.
Key highlights
- Subtitle-first architecture: extracts existing captions before falling back to local Whisper transcription
- Supports 30+ video platforms via
yt-dlpplus local uploads up to 200 MB (.mp4,.mp3,.txt, and others) - BYO LLM: configure any OpenAI-compatible base URL and key in the browser; the UI fetches and lists available models automatically
- Conditional translation: auto-translates transcripts when the requested summary language differs from the source
- Includes a sanitizer module (
llm_sanitize.py) to strip boilerplate from LLM outputs before showing them to you
Caveats
- The README notes that long videos can take 30–60+ minutes and recommends a production mode to prevent SSE disconnections, so patience (or smaller Whisper models) is required for lengthy content.
- It is fundamentally an orchestration layer around
yt-dlp, FFmpeg, Faster-Whisper, and an OpenAI-style API; the heavy lifting is delegated, not reinvented.
Verdict Good for developers who want a private, self-hosted alternative to cloud transcription services and already have an LLM API key or local endpoint. Skip it if you need a fully offline, zero-API solution or a polished SaaS experience.
Frequently asked
- What is wendy7756/AI-Video-Transcriber?
- It transcribes and summarizes videos by extracting existing subtitles before ever touching Whisper, then hands the text to any OpenAI-compatible LLM you configure.
- Is AI-Video-Transcriber open source?
- Yes — wendy7756/AI-Video-Transcriber is open source, released under the Apache-2.0 license.
- What language is AI-Video-Transcriber written in?
- wendy7756/AI-Video-Transcriber is primarily written in Python.
- How popular is AI-Video-Transcriber?
- wendy7756/AI-Video-Transcriber has 3k stars on GitHub and is currently accelerating.
- Where can I find AI-Video-Transcriber?
- wendy7756/AI-Video-Transcriber is on GitHub at https://github.com/wendy7756/AI-Video-Transcriber.