vllm-project/vllm-omni
vLLM grows eyes, ears, and a paintbrush
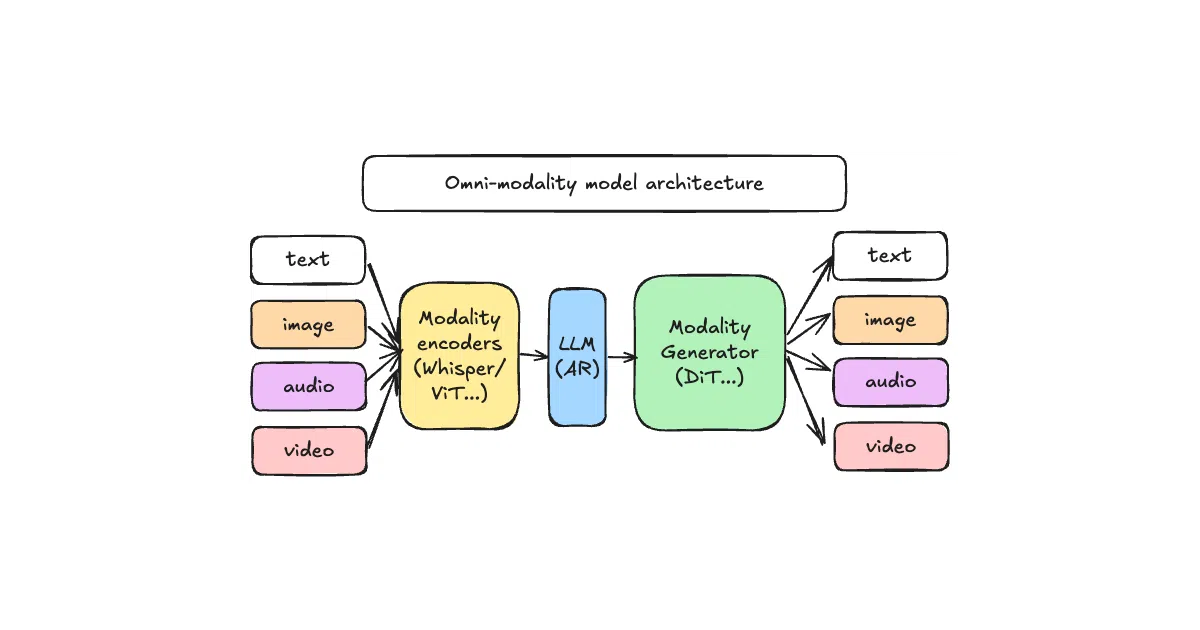
vLLM-Omni extends the text-only vLLM engine into a disaggregated serving stack for models that consume and generate text, images, video, and audio.
Velocity · 7d
+9.9
★ / day
Trend
↘cooling
star history
What it does
vLLM-Omni is a serving framework that bolts multimodal capabilities onto the vLLM inference engine. It handles models that ingest and emit text, images, video, and audio—including hybrid workflows that mix autoregressive generation with diffusion transformers. The project exposes an OpenAI-compatible API server with streaming outputs, so querying a model like Qwen-Omni can return mixed text, speech, or image responses.
The interesting bit
Instead of treating diffusion and autoregressive models as separate services, vLLM-Omni disaggregates them into stages of a single pipeline orchestrated by an OmniConnector. Resources are allocated dynamically across stages, and pipelined execution overlap keeps throughput from collapsing when the workload switches from token prediction to image denoising.
Key highlights
- Serves text, image, video, and audio through one unified stack
- Extends vLLM’s KV-cache management to non-autoregressive diffusion transformers (DiT)
- Disaggregated architecture with dynamic resource allocation across heterogeneous stages
- OpenAI-compatible API with streaming multimodal outputs
- Runs on CUDA, ROCm, MUSA, NPU, and XPU backends
- Supports HuggingFace models including Qwen-Omni, Qwen3-TTS, Bagel, MiMo-Audio, and GLM-Image
Verdict
Reach for this if you are serving any-to-any multimodal models that straddle LLM reasoning and diffusion generation. If your workloads are purely text-based, upstream vLLM already has you covered.
Frequently asked
- What is vllm-project/vllm-omni?
- vLLM-Omni extends the text-only vLLM engine into a disaggregated serving stack for models that consume and generate text, images, video, and audio.
- Is vllm-omni open source?
- Yes — vllm-project/vllm-omni is open source, released under the Apache-2.0 license.
- What language is vllm-omni written in?
- vllm-project/vllm-omni is primarily written in Python.
- How popular is vllm-omni?
- vllm-project/vllm-omni has 5.7k stars on GitHub and is currently cooling off.
- Where can I find vllm-omni?
- vllm-project/vllm-omni is on GitHub at https://github.com/vllm-project/vllm-omni.