vllm-project/llm-compressor
Shrink LLMs for vLLM without losing your mind
A one-stop quantization toolkit that bridges research algorithms and production inference.
Not currently ranked — collecting fresh signals.
star history
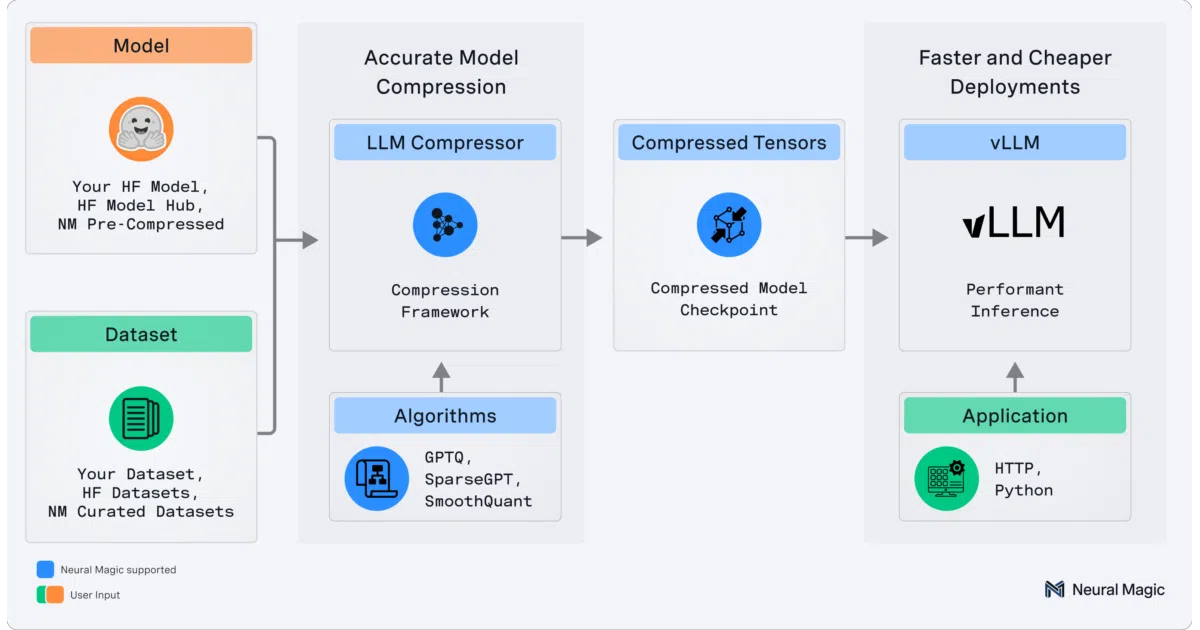
What it does
llmcompressor applies compression algorithms—GPTQ, AWQ, SmoothQuant, AutoRound, and others—to Hugging Face transformers models, then exports them in a compressed-tensors format that vLLM can run directly. It handles weights, activations, KV cache, and even attention layers, with DDP and disk offloading for models too large to fit in CPU memory.
The interesting bit
The library sits at an awkward but useful intersection: it wraps a zoo of quantization research into a single oneshot() API, yet targets one specific inference engine. The “model-free PTQ” pathway is a pragmatic escape hatch for models that lack standard HF definitions—useful when oneshot chokes on something like Mistral Large 3.
Key highlights
- Supports int8, fp8, fp4 (NVFP4 and MXFP4), and microscale formats across weights, activations, and KV cache
- Distributed GPTQ with DDP to speed up calibration on multi-GPU setups
- Disk offloading and sequential loading for models that exceed available memory
- Pre-quantized checkpoints published for DeepSeek-V4-Flash, Kimi-K2.6, Qwen3.5/3.6, and Gemma 4
- Vision-language and audio-language quantization examples included
Caveats
- MXFP4 with activation quantization is not yet supported in vLLM for compressed-tensors models
- Model-free PTQ currently limited to data-free pathways (FP8 only)
- Some newer model support requires bleeding-edge transformers versions
Verdict
Worth a look if you’re already committed to vLLM and need to squeeze models onto fewer GPUs or less VRAM. Skip it if you need a framework-agnostic quantization tool or want to run compressed models elsewhere.
Frequently asked
- What is vllm-project/llm-compressor?
- A one-stop quantization toolkit that bridges research algorithms and production inference.
- Is llm-compressor open source?
- Yes — vllm-project/llm-compressor is open source, released under the Apache-2.0 license.
- What language is llm-compressor written in?
- vllm-project/llm-compressor is primarily written in Python.
- How popular is llm-compressor?
- vllm-project/llm-compressor has 3.6k stars on GitHub.
- Where can I find llm-compressor?
- vllm-project/llm-compressor is on GitHub at https://github.com/vllm-project/llm-compressor.