varunvasudeva1/llm-server-docs
A Debian blueprint for a private, cloud-like AI server
Documentation that glues together a dozen open-source tools so you can run a fully local ChatGPT alternative without wiring it all yourself.
Not currently ranked — collecting fresh signals.
star history
What it does
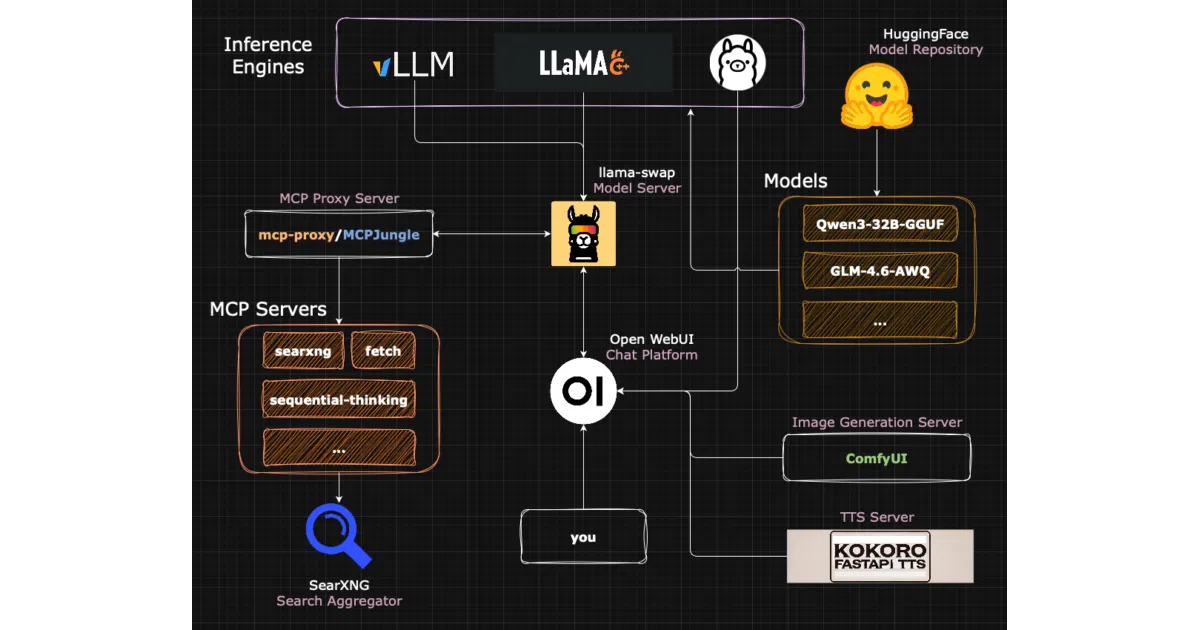
This repository is an opinionated, end-to-end guide for turning a fresh Debian install into a self-hosted LLM server. It stitches together inference engines (Ollama, llama.cpp, vLLM), a chat interface (Open WebUI), web search (SearXNG), image generation (ComfyUI), text-to-speech (Kokoro FastAPI), and MCP proxies into one cohesive stack. The result is meant to feel like a cloud provider’s chat platform, except your data never leaves the box.
The interesting bit
Rather than dumping a Docker Compose file and wishing you luck, the guide acts like a systems-engineering recipe: it covers GPU power limiting, systemd services, firewall rules, Tailscale exit nodes, and Docker hardening. The author admits they are a Linux beginner, which makes the meticulous, step-by-step tone either charming or tedious depending on your shell fluency.
Key highlights
- Mix-and-match inference backends (
Ollama,llama.cpp,vLLM) withllama-swapfor hot-swapping models - Full peripheral stack: web search, RAG, MCP servers, image generation, and voice output tied into
Open WebUI - Security and remote access baked in: SSH hardening, firewall config, Docker restrictions, and Tailscale
- 24/7 operation focus with boot scripts and GPU power-limiting to cut electricity bills
- CPU-only and AMD GPU paths are documented, though the reference build uses dual Nvidia RTX 3090s
Caveats
- The author explicitly warns readers to double-check every command; this is curated documentation, not a tested installer or package
- Tool churn is treated as a feature, not a bug: there is a lengthy “Updating” section because the ecosystem moves fast
Verdict
A solid weekend project for developers with spare hardware who want a private, always-on AI workstation. Not for anyone hoping for a one-click SaaS experience.
Frequently asked
- What is varunvasudeva1/llm-server-docs?
- Documentation that glues together a dozen open-source tools so you can run a fully local ChatGPT alternative without wiring it all yourself.
- Is llm-server-docs open source?
- Yes — varunvasudeva1/llm-server-docs is open source, released under the MIT license.
- How popular is llm-server-docs?
- varunvasudeva1/llm-server-docs has 815 stars on GitHub.
- Where can I find llm-server-docs?
- varunvasudeva1/llm-server-docs is on GitHub at https://github.com/varunvasudeva1/llm-server-docs.