udibr/headlines
Neural headline writer that sometimes copies your homework
A 2015-era Keras notebook that teaches RNNs to summarize news articles by learning when to paraphrase and when to just lift words from the source text.
Not currently ranked — collecting fresh signals.
star history
What it does
This is a faithful reproduction of a 2015 arXiv paper on generating news headlines with recurrent neural networks. Feed it article ledes, train an RNN with attention in Keras, and it spits out headline-length summaries. The whole pipeline lives in Jupyter notebooks: build a GloVe-backed vocabulary, train the model, then generate text.
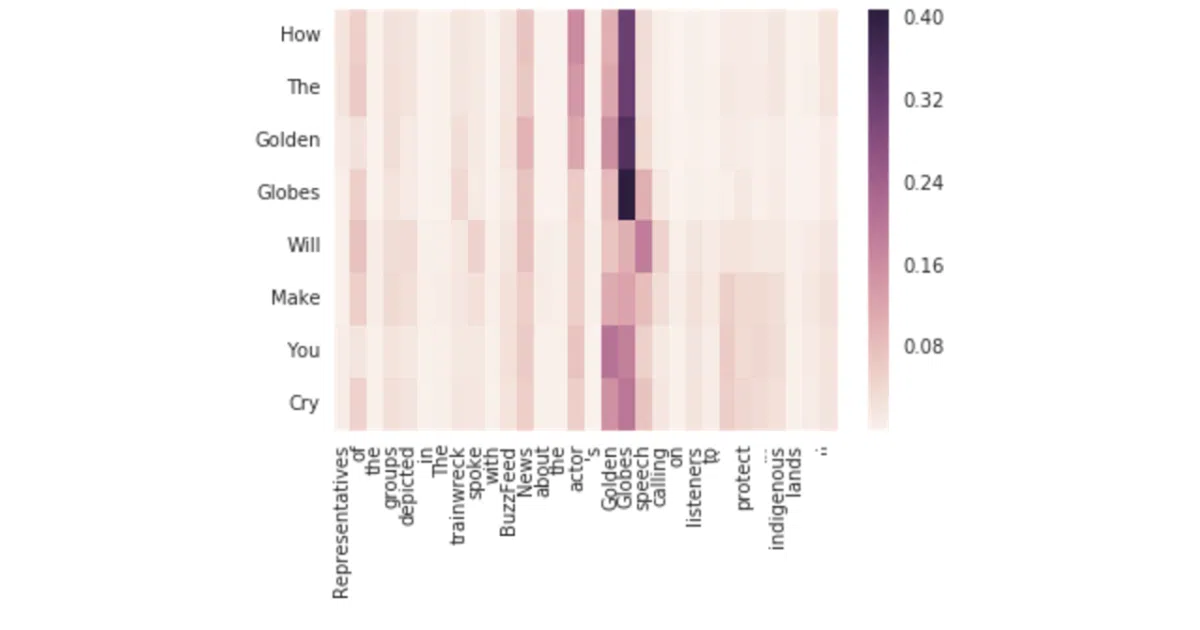
The interesting bit
The author added a practical twist the original paper skipped: out-of-vocabulary words get copied directly from the source article rather than mangled into nearest-neighbor gibberish. The attention visualization shows exactly which source words the model fixated on for each generated token — useful for debugging why your headline about trade policy suddenly mentions “avocados.”
Key highlights
- Attention mechanism with weight visualization
- Copy mechanism for OOV words (not in the original paper)
- GloVe embeddings for initialization
- ~684K training examples used by the author
- Pure Keras/Jupyter workflow, no hidden framework magic
Caveats
- Requires you to already have tokenized article/headline pairs in a pickle file; no data downloader included
- The showcased examples are explicitly cherry-picked — the README admits this
python-Levenshteindependency for unclear reasons (not explained)- Keras circa 2015; modern TensorFlow/PyTorch users will need patience
Verdict
Worth a look if you’re teaching or studying classic seq2seq+attention architectures, or need a baseline to beat. Skip it if you want production-ready abstractive summarization — this is a paper reproduction with training wheels, not a maintained library.
Frequently asked
- What is udibr/headlines?
- A 2015-era Keras notebook that teaches RNNs to summarize news articles by learning when to paraphrase and when to just lift words from the source text.
- Is headlines open source?
- Yes — udibr/headlines is open source, released under the MIT license.
- What language is headlines written in?
- udibr/headlines is primarily written in Jupyter Notebook.
- How popular is headlines?
- udibr/headlines has 523 stars on GitHub.
- Where can I find headlines?
- udibr/headlines is on GitHub at https://github.com/udibr/headlines.