ucbepic/docetl
ETL pipelines that actually talk back
DocETL turns LLMs into pipeline operators you can prototype in a browser and ship to production.
Not currently ranked — collecting fresh signals.
star history
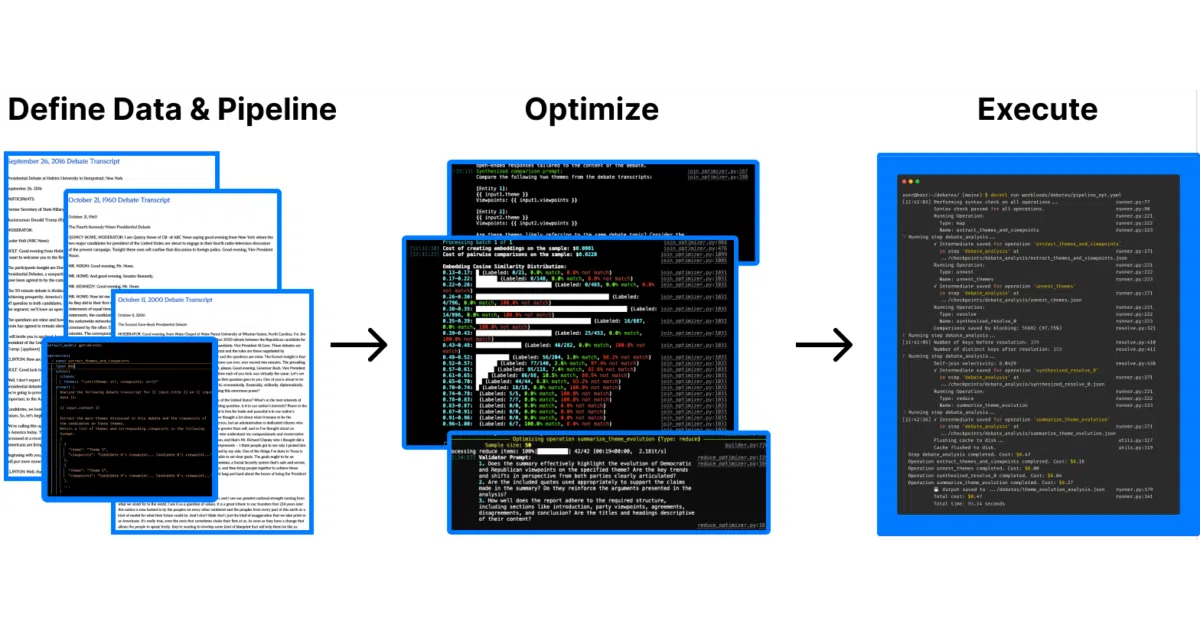
What it does DocETL is a Python framework for building document-processing pipelines where the transforms are LLM prompts rather than SQL or Python functions. It ships with DocWrangler, a browser-based playground for iterating on prompts step-by-step, then exporting the final pipeline config to run headless in production.
The interesting bit The split personality is the point: the same YAML-ish pipeline definition runs in a clicky UI for debugging and from the CLI for batch jobs. The README even suggests using Claude Code to write the pipeline that will later feed Claude via API—recursive automation with a straight face.
Key highlights
- DocWrangler playground: hosted at docetl.org/playground, or run locally via Docker (
make docker) - Production runner:
pip install docetl, load the exported config, execute - Multi-provider: OpenAI out of the box, AWS Bedrock via liteLLM prefixing
- Two .env files: root
.envfor the Python backend,website/.env.localfor the TypeScript frontend—easy to mix up, so the README warns you twice - Paper-backed: arXiv preprint linked for the academically curious
Caveats
- Requires Python 3.10+ and an OpenAI key just to get started; BYO API budget
- Local setup is Makefile-heavy; the “manual” path still expects
uv, pre-commit, and Node dependencies - The hosted playground is convenient, but any non-trivial run sends your documents to a third-party LLM
Verdict Grab this if you’re drowning in unstructured documents and want to replace brittle regexes with prompt-based transforms you can iterate on visually. Skip it if your data is already clean, tabular, or you flinch at per-token pricing on every pipeline run.
Frequently asked
- What is ucbepic/docetl?
- DocETL turns LLMs into pipeline operators you can prototype in a browser and ship to production.
- Is docetl open source?
- Yes — ucbepic/docetl is open source, released under the MIT license.
- What language is docetl written in?
- ucbepic/docetl is primarily written in Python.
- How popular is docetl?
- ucbepic/docetl has 3.9k stars on GitHub.
- Where can I find docetl?
- ucbepic/docetl is on GitHub at https://github.com/ucbepic/docetl.