turboderp/exllama
4-Bit Llama That Compiles Its Own CUDA Kernels
A standalone rewrite of the Llama inference stack that trades Hugging Face overhead for leaner VRAM usage and on-the-fly CUDA kernels.
Not currently ranked — collecting fresh signals.
star history
What it does
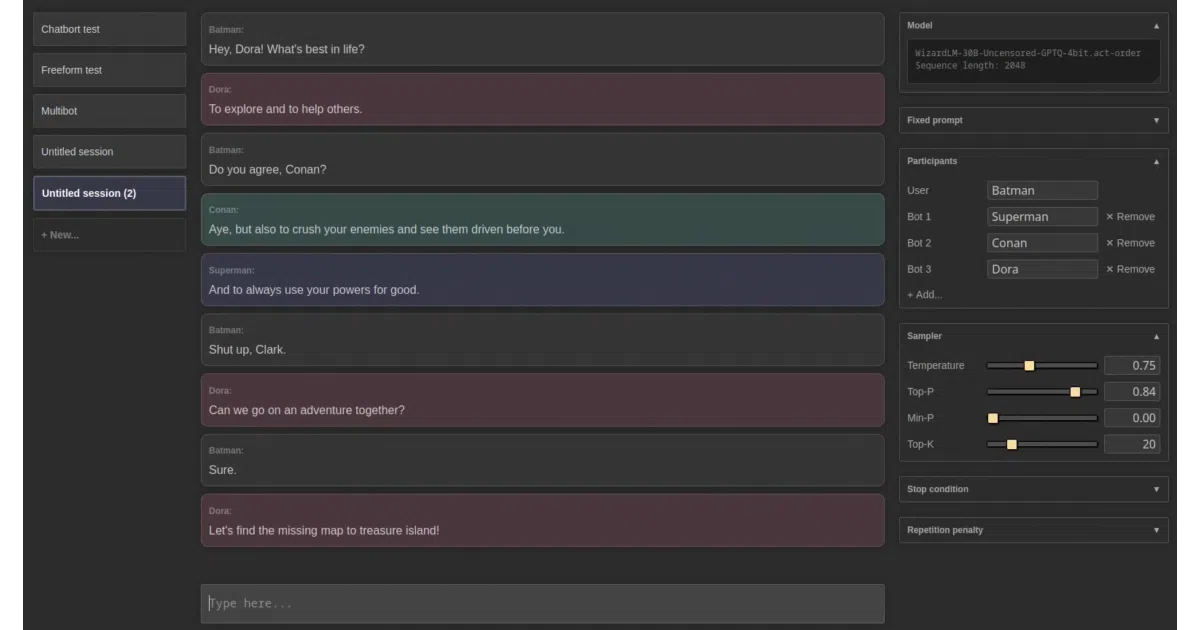
ExLlama is a standalone Python/C++/CUDA inference engine for Llama-family models that have been squashed to 4-bit GPTQ weights. It rips out the standard Hugging Face transformers path and replaces it with a leaner stack designed to fit bigger models into less VRAM while keeping token generation fast on modern NVIDIA GPUs. The project also ships with a minimal web UI and chatbot example, plus Docker support for isolated deployment.
The interesting bit
Rather than forcing you to build a CUDA extension by hand, ExLlama compiles its custom kernels at runtime on first load and caches them in Torch’s extension directory. That trades a brief initial wait for zero manual build steps. It also handles sharded safetensors checkpoints and can split a 70B parameter model across two GPUs with per-card memory limits.
Key highlights
- Benchmarks on an RTX 4090 show a 33B model running inside roughly 21 GB of VRAM, leaving breathing room for a desktop environment.
- Prompt-processing speeds hit thousands of tokens per second for smaller models and stay above 900 t/s for 70B variants spread across two GPUs.
- Supports sharded models via
safetensorsand granular dual-GPU layer offloading. - Includes a minimal web UI—its JavaScript was mostly written by ChatGPT, per the author, but multibot mode works.
- ExLlamaV2 already exists as a successor; this repo remains useful for features V2 has not yet absorbed.
Caveats
- The author explicitly labels the project a work in progress.
- Pascal-era and older NVIDIA GPUs are poor performers here; the README steers owners toward AutoGPTQ or GPTQ-for-LLaMa instead.
- ROCm support is theoretical only, since the author has no AMD hardware to test or optimize on.
Verdict
Grab this if you need to run quantized Llama variants on a single modern NVIDIA GPU—or two—and want to dodge the usual transformers boilerplate. Skip it if you are on older NVIDIA hardware, need AMD ROCm certainty, or want a polished, finished product; in that case, check whether ExLlamaV2 already covers your use case.
Frequently asked
- What is turboderp/exllama?
- A standalone rewrite of the Llama inference stack that trades Hugging Face overhead for leaner VRAM usage and on-the-fly CUDA kernels.
- Is exllama open source?
- Yes — turboderp/exllama is open source, released under the MIT license.
- What language is exllama written in?
- turboderp/exllama is primarily written in Python.
- How popular is exllama?
- turboderp/exllama has 2.9k stars on GitHub.
- Where can I find exllama?
- turboderp/exllama is on GitHub at https://github.com/turboderp/exllama.