transitive-bullshit/yt-semantic-search
Search podcasts by vibe, not keyword
A reference stack for turning any YouTube playlist into an embedding-powered search engine, built around the All-In Podcast.
Not currently ranked — collecting fresh signals.
star history
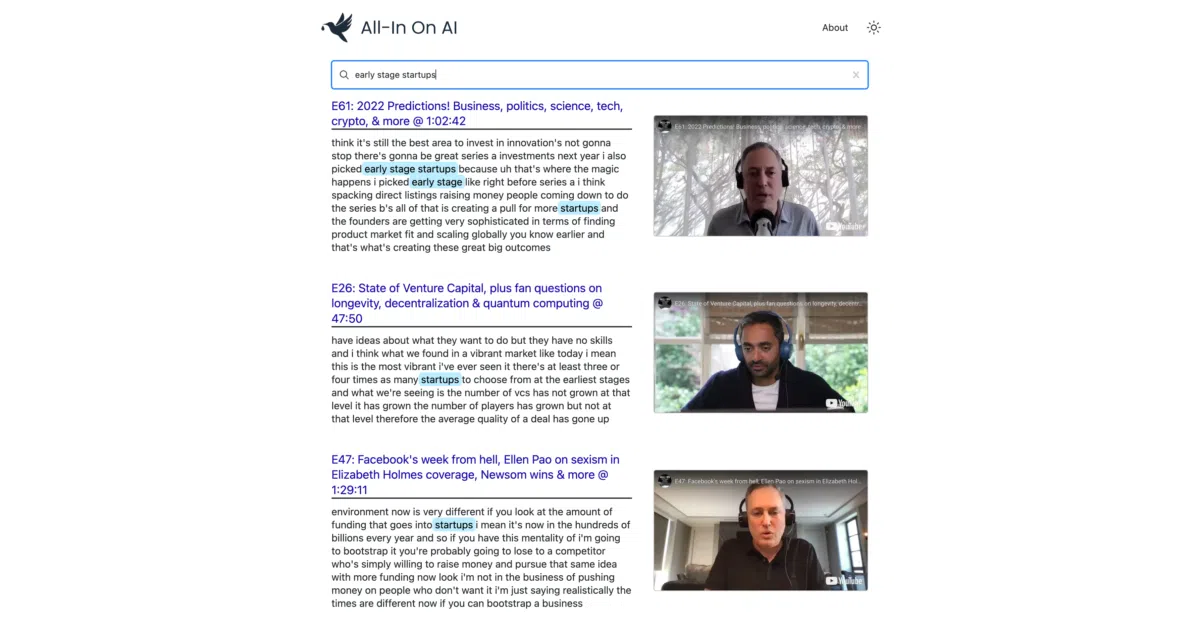
What it does
Downloads transcripts from a YouTube playlist, chunks them into ~100-token slices, and pushes OpenAI text-embedding-ada-002 vectors into Pinecone. A Next.js frontend on Vercel lets you query by meaning—“sweater karen” or “poker story from last night”—and jump to the exact timestamp. CLI scripts handle the ingest pipeline; thumbnail generation is optional and slow.
The interesting bit
The transcript fetch is “hacky HTML scraping” because YouTube’s API locks captions behind OAuth. The author knows this is brittle and flags Whisper as the proper fix, which is a refreshing honesty in a space full of hand-waved infrastructure.
Key highlights
- ~17,575 embeddings across 108 episodes, 1536-dimensional vectors
- Supports sorting by recency vs. relevancy (noted in TODO, partially implemented per intro)
- Thumbnails via headless Puppeteer + Google Cloud Storage, with
lqip-modernplaceholders - MIT licensed; author openly asks for sponsors to cover API bills
- Inspired by a similar Huberman Lab project—this is a pattern, not an anomaly
Caveats
- Transcript scraping breaks when YouTube changes markup; some episodes lack auto-captures and are silently skipped
- Thumbnail generation takes ~2 hours and needs stable internet
- “A better solution would be to use Whisper” is literally in the README
Verdict
Worth studying if you’re building RAG over video content and want to see where the rough edges actually live. Skip it if you need production-grade transcription today; the pipeline is a working sketch, not a product.
Frequently asked
- What is transitive-bullshit/yt-semantic-search?
- A reference stack for turning any YouTube playlist into an embedding-powered search engine, built around the All-In Podcast.
- Is yt-semantic-search open source?
- Yes — transitive-bullshit/yt-semantic-search is open source, released under the MIT license.
- What language is yt-semantic-search written in?
- transitive-bullshit/yt-semantic-search is primarily written in TypeScript.
- How popular is yt-semantic-search?
- transitive-bullshit/yt-semantic-search has 542 stars on GitHub.
- Where can I find yt-semantic-search?
- transitive-bullshit/yt-semantic-search is on GitHub at https://github.com/transitive-bullshit/yt-semantic-search.