tracel-ai/burn
Burn wraps autodiff and kernel fusion around any hardware backend
It exists so you can train on CUDA and deploy the same Rust model to WebAssembly, Metal, or bare metal without porting.
Velocity · 7d
+5.4
★ / day
Trend
→steady
star history
What it does
Burn is a Rust deep learning framework that handles both training and inference. It abstracts over hardware through a generic Backend trait, letting the same model run on CUDA, Metal, Vulkan, WebGPU, or even no-std embedded environments. It also imports ONNX and PyTorch weights so you aren’t forced to rebuild existing models from scratch.
The interesting bit
The architecture treats capabilities like autodifferentiation, kernel fusion, and remote distributed execution as backend decorators—composable layers wrapped around a base compute backend at the type level. This means you can strap autodiff onto a GPU backend, or wrap that fused-autodiff stack in a remote client, and the compiler will refuse to let you call backward on an inference-only backend.
Key highlights
- Supports a wide matrix of hardware: Nvidia CUDA, AMD ROCm, Apple Metal, Intel/Qualcomm Vulkan, and browser WebGPU via backend-specific implementations.
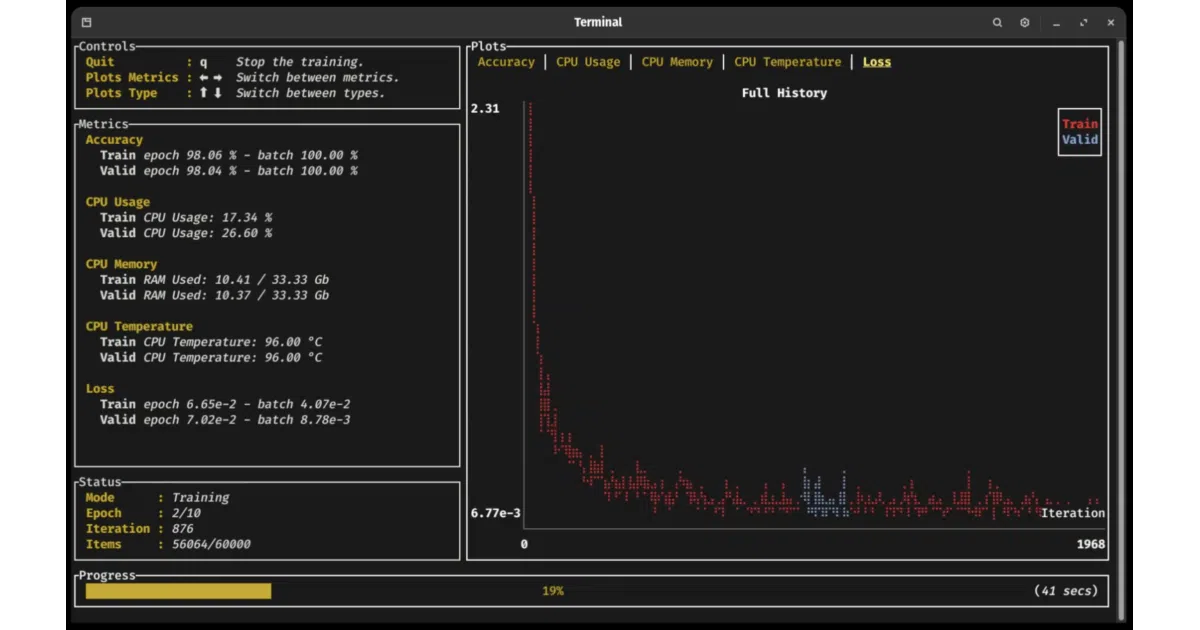
- Includes a terminal-based training dashboard built on Ratatui for monitoring metrics without external tools.
- Can import ONNX models and PyTorch/Safetensors weights, converting them to native Rust code that inherits Burn’s optimizations.
- Runs inference in the browser through WebAssembly and on embedded devices via
no_stdsupport, though only through the Flex backend. - Offers a dedicated benchmarking suite,
burn-bench, for comparing backend performance.
Caveats
- The
wgpubackend can hit recursive type evaluation errors during compilation due to deep trait nesting; the README suggests raising Rust’s recursion limit as a workaround. - ONNX support is actively developed but currently covers only a limited set of operators.
- The Remote backend for distributed execution is still in beta.
Verdict
Worth a look if you want a single Rust codebase that travels from Nvidia training rigs to browsers and bare-metal devices. Skip it if you need mature, Python-first ecosystem tooling or immediate, broad ONNX operator coverage.
Frequently asked
- What is tracel-ai/burn?
- It exists so you can train on CUDA and deploy the same Rust model to WebAssembly, Metal, or bare metal without porting.
- Is burn open source?
- Yes — tracel-ai/burn is open source, released under the Apache-2.0 license.
- What language is burn written in?
- tracel-ai/burn is primarily written in Rust.
- How popular is burn?
- tracel-ai/burn has 15.6k stars on GitHub and is currently holding steady.
- Where can I find burn?
- tracel-ai/burn is on GitHub at https://github.com/tracel-ai/burn.