timescale/pgai
PostgreSQL that embeds itself, then sunsets itself
A Python library that turns Postgres into a self-managing retrieval engine for RAG—except the maintainers have already called last orders.
Not currently ranked — collecting fresh signals.
star history
What it does
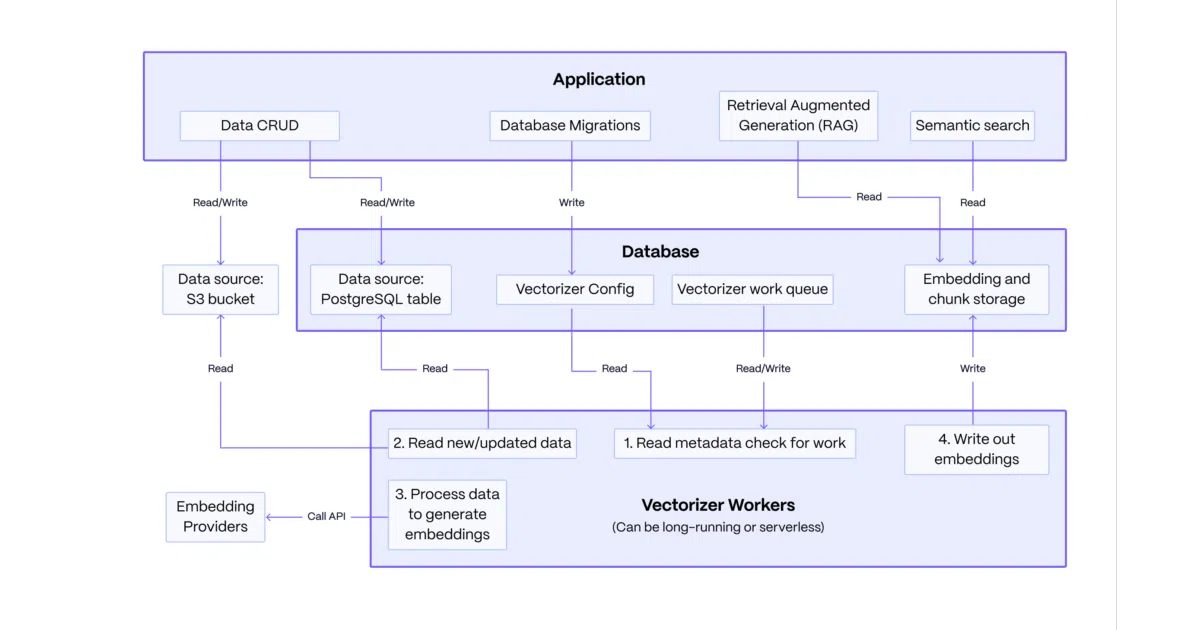
pgai installs into PostgreSQL and runs background workers that automatically generate and synchronize vector embeddings from your tables. You write a SQL declaration—something like CREATE INDEX, but for embeddings—and the system handles chunking, batching, retrying on rate limits, and keeping vectors in sync as source data changes. It also offers a “Semantic Catalog” for natural-language-to-SQL translation.
The interesting bit The architecture decouples your application writes from embedding generation. The database owns the queue; stateless workers consume it. If OpenAI is having a bad day, your app keeps writing rows while the workers back off and retry. The README’s own analogy is apt: think of it as “declaring an index,” except the index lives in an embedding model.
Key highlights
- Embeddings stay synchronized automatically as table data changes, without application code managing the pipeline.
- Built-in resilience: handles model failures, rate limits, and latency spikes via batching and retries.
- Works with any PostgreSQL host—Timescale Cloud, RDS, Supabase, self-hosted.
- Includes a Semantic Catalog feature for text-to-SQL generation against your schema.
- Stateless worker model means you can scale embedding throughput independently of your database.
Caveats
- The project is explicitly unmaintained as of February 2026. The README leads with this in an
<h1>; do not build new production systems on it without a fork-and-own plan. - Requires running separate vectorizer workers unless you’re on Timescale Cloud, adding operational complexity.
- The quickstart defaults to OpenAI; other providers are supported but less prominently documented.
Verdict Worth studying if you’re designing embedding pipelines inside Postgres, or if you already run Timescale and can absorb the maintenance burden yourself. Everyone else should treat it as a reference architecture with working code, not a dependency.
Frequently asked
- What is timescale/pgai?
- A Python library that turns Postgres into a self-managing retrieval engine for RAG—except the maintainers have already called last orders.
- Is pgai open source?
- Yes — timescale/pgai is open source, released under the PostgreSQL license.
- What language is pgai written in?
- timescale/pgai is primarily written in PLpgSQL.
- How popular is pgai?
- timescale/pgai has 5.8k stars on GitHub.
- Where can I find pgai?
- timescale/pgai is on GitHub at https://github.com/timescale/pgai.