thiswillbeyourgithub/wdoc
A psychiatry resident built a RAG pipeline with named LLM personas
wdoc tackles the messy reality of querying across PDFs, Anki decks, YouTube videos, and audio transcripts without pretending your documents are clean.
Not currently ranked — collecting fresh signals.
star history
What it does
wdoc is a Python RAG system for summarizing and querying heterogeneous document collections. It ingests 15+ file types—PDFs, EPUBs, Anki flashcards, YouTube videos, audio recordings, even web search results via DuckDuckGo—then runs retrieval-augmented generation with explicit source attribution. You can point it at a single PDF or a jumble of formats and ask questions that pull from all of them simultaneously.
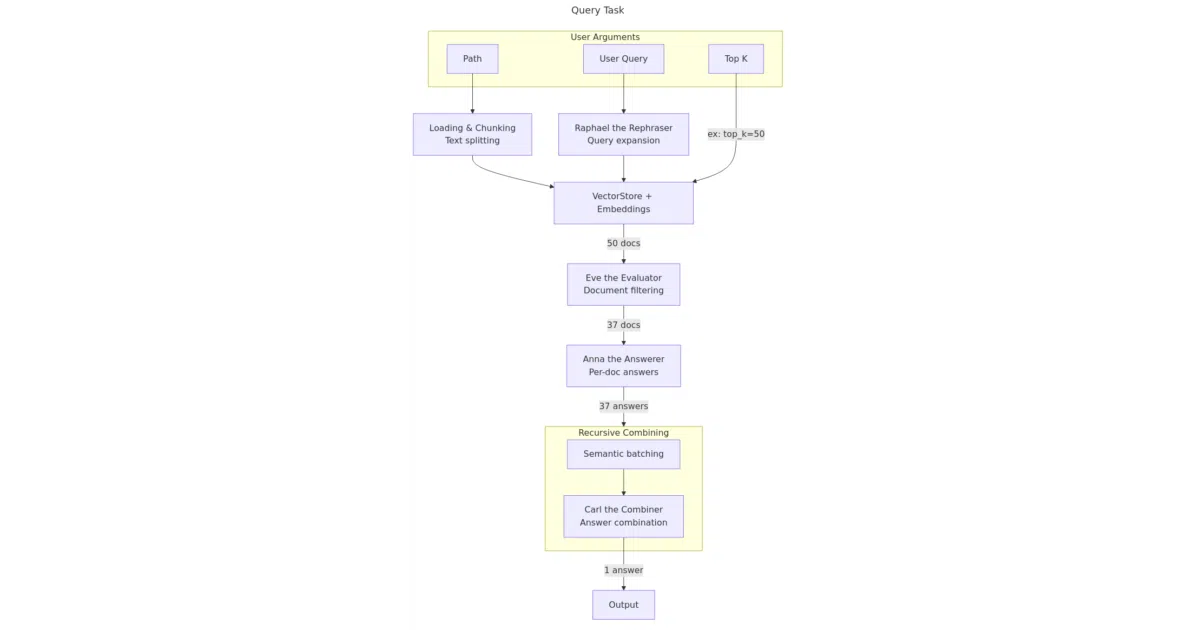
The interesting bit
The pipeline assigns names and roles to LLMs at each stage: Raphael the Rephraser generates query variants, Eve the Evaluator filters retrieved chunks for relevance, Anna the Answerer extracts answers per document, and Carl the Combiner merges them using semantic clustering and hierarchical leaf ordering. It’s a rare case where the system prompts are architecturally exposed rather than hidden, letting users tweak each persona’s behavior. The author also overloads Python sockets in “private mode” to block outbound connections—paranoid, but thorough.
Key highlights
- Dual-LLM cost control: Uses a cheap model for broad retrieval and an expensive one only for final answers, with automatic expansion of
top_kif relevance stays high. - Semantic batching: Intermediate answers are clustered and ordered by meaning before combination, not just concatenated.
- Recursive summarization: Chunk-level summaries feed forward with context, and whole documents can be recursively re-summarized for very long inputs.
- Multiple interfaces: CLI via
uvx, Python library, Gradio Docker UI, and an Open-WebUI Tool. - LLM-agnostic: Backed by LiteLLM; supports 100+ models including local ones via Ollama.
Caveats
- The Docker web UI is labeled “experimental” in the README.
- The default LLM choices (DeepSeek via OpenRouter) and the
top_k=auto_200_500heuristic may need tuning for your corpus and budget. - The author notes many “minor quick-to-fix bugs” and actively requests testers; the dev branch has more features but less stability.
Verdict
Worth a look if you’re drowning in mixed-format research materials and existing RAG tools keep choking on your Anki deck plus your PDF folder. Skip it if you need a polished, zero-config SaaS experience—this is a power user’s tinkerer’s toolkit with rough edges still being sanded.
Frequently asked
- What is thiswillbeyourgithub/wdoc?
- wdoc tackles the messy reality of querying across PDFs, Anki decks, YouTube videos, and audio transcripts without pretending your documents are clean.
- Is wdoc open source?
- Yes — thiswillbeyourgithub/wdoc is open source, released under the AGPL-3.0 license.
- What language is wdoc written in?
- thiswillbeyourgithub/wdoc is primarily written in Python.
- How popular is wdoc?
- thiswillbeyourgithub/wdoc has 519 stars on GitHub.
- Where can I find wdoc?
- thiswillbeyourgithub/wdoc is on GitHub at https://github.com/thiswillbeyourgithub/wdoc.