texttron/hyde
Search without labels: GPT hallucinates documents, and it works
A retrieval system that skips human relevance judgments by having a language model invent fake documents, then searches for real ones that look similar.
Not currently ranked — collecting fresh signals.
star history
What it does
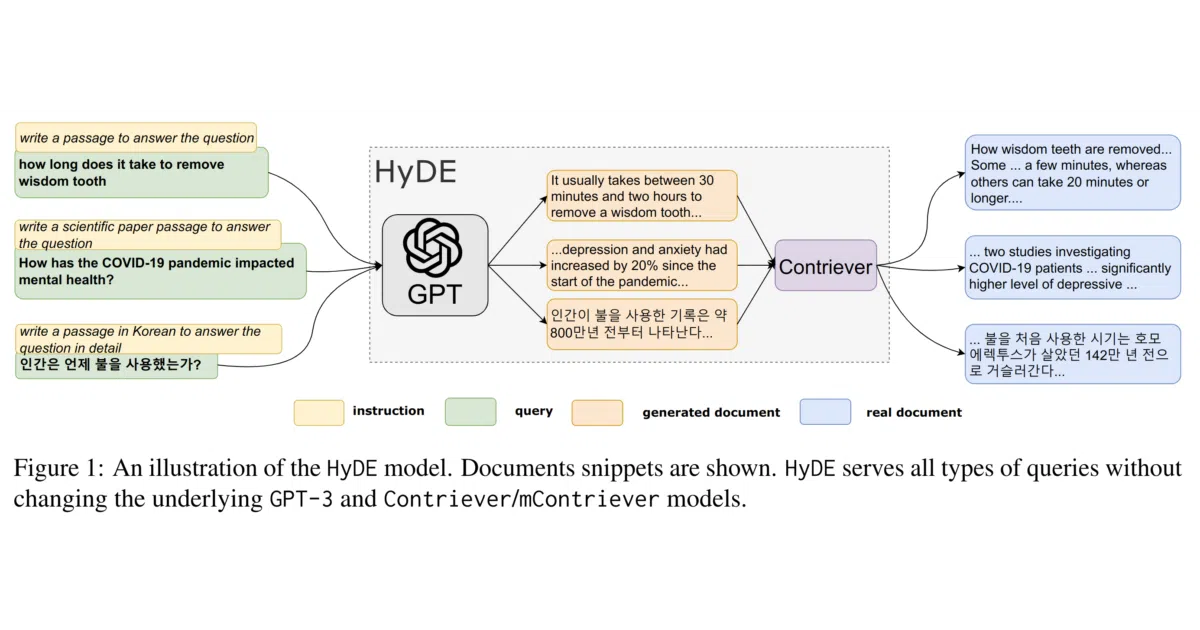
HyDE answers search queries by first asking GPT-3 to hallucinate a plausible document, then encoding that fiction with an unsupervised retriever (Contriever) to find real documents in the same embedding neighborhood. No human relevance labels required at any stage.
The interesting bit
The counterintuitive trick: a made-up document often captures the semantic intent of a query better than the query itself, especially for short or ambiguous searches. The unsupervised retriever never sees the original query—only GPT-3’s synthetic prose.
Key highlights
- Outperforms vanilla Contriever across tasks and languages (per the paper)
- Built on Pyserini for dense retrieval; uses a prebuilt Contriever FAISS index for MS MARCO
- Two notebooks provided:
hyde-dl19.ipynbfor TREC DL19 evaluation,hyde-demo.ipynbfor a walkthrough pipeline - Requires only an OpenAI API key and the downloaded index to run
- Paper authors: Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan (2022)
Caveats
- Hard dependency on GPT-3 API; costs and latency scale with query volume
- README is minimal—no mention of exact performance numbers, other LLM support, or whether hallucinated documents can drift for edge-case queries
Verdict
Worth a look if you’re building zero-shot retrieval and labeling relevance judgments is impossible or expensive. Skip it if you need deterministic, explainable retrieval or can’t stomach API costs for synthetic document generation.
Frequently asked
- What is texttron/hyde?
- A retrieval system that skips human relevance judgments by having a language model invent fake documents, then searches for real ones that look similar.
- Is hyde open source?
- Yes — texttron/hyde is an open-source project tracked on heatdrop.
- What language is hyde written in?
- texttron/hyde is primarily written in Jupyter Notebook.
- How popular is hyde?
- texttron/hyde has 583 stars on GitHub.
- Where can I find hyde?
- texttron/hyde is on GitHub at https://github.com/texttron/hyde.