tensorlayer/seq2seq-chatbot
Chatbot in 200 lines, for better and worse
A minimal seq2seq implementation that trades sophistication for clarity, producing replies that range from politely confused to accidentally political.
Not currently ranked — collecting fresh signals.
star history
What it does
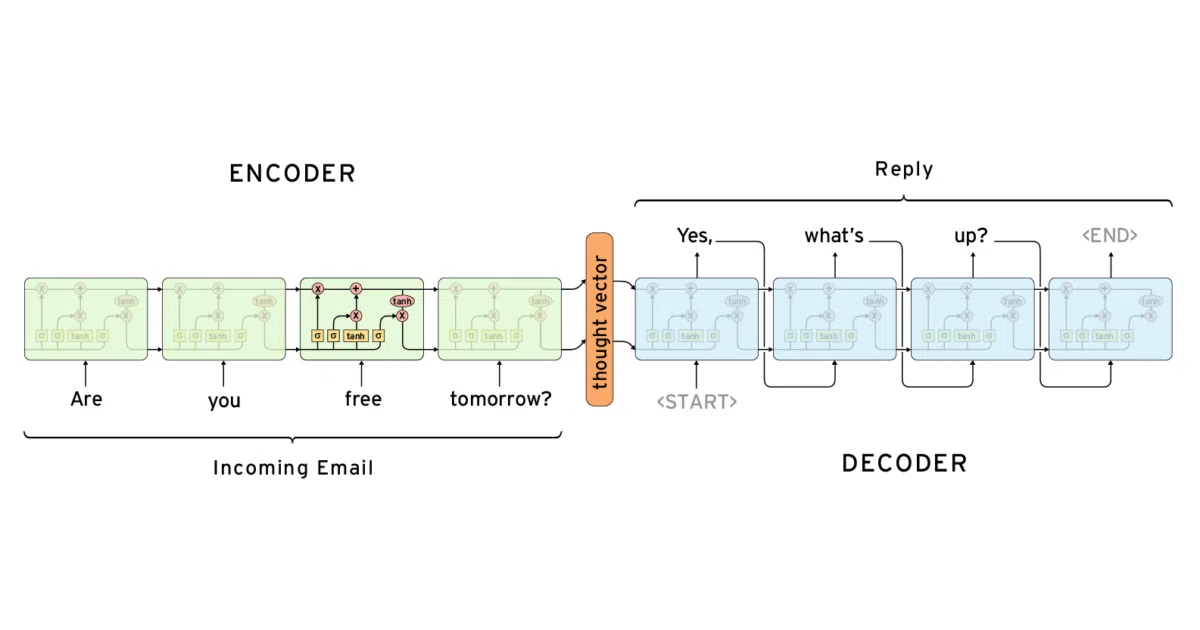
Implements a Twitter/Cornell-Movie chatbot using encoder-decoder LSTMs in roughly 200 lines of Python. Feed it a sentence, get back five candidate replies ranked by the model’s confidence. The training script is a single python3 main.py away, assuming you’ve got TensorFlow 2.0+ and TensorLayer 2.0+ installed.
The interesting bit
The README doesn’t hide its lineage: it sends you to three classic blog posts (Karpathy on RNNs, colah on LSTMs, Suriya Deepan’s practical seq2seq guide) before you even glance at the code. This is pedagogy by reference—useful if you want to map the implementation back to first principles, less so if you were hoping for inline documentation.
Key highlights
- Explicitly targets Python 3.6 and TensorFlow 2.0 era, which already dates it somewhat
- Trains on two public corpora: Twitter and Cornell Movie Dialogs
- Generates multiple reply candidates per query, not just a greedy argmax
- Output samples show the model grasping sentiment (“thank you so much”) while occasionally hallucinating opinions about political figures
- TensorLayer abstraction keeps the line count low
Caveats
- No mention of attention mechanisms, beam search, or transformer alternatives—pure vanilla seq2seq
- The political reply example (“trump needs to be president”) suggests the training data wasn’t carefully filtered; deploy at your own risk
- No evaluation metrics, loss curves, or training time estimates provided
Verdict
Good for someone who wants to touch a working seq2seq pipeline without drowning in HuggingFace abstractions. Skip it if you need production-grade dialogue systems or modern architecture; the 841 stars reflect educational value, not state-of-the-art performance.
Frequently asked
- What is tensorlayer/seq2seq-chatbot?
- A minimal seq2seq implementation that trades sophistication for clarity, producing replies that range from politely confused to accidentally political.
- Is seq2seq-chatbot open source?
- Yes — tensorlayer/seq2seq-chatbot is an open-source project tracked on heatdrop.
- What language is seq2seq-chatbot written in?
- tensorlayer/seq2seq-chatbot is primarily written in Python.
- How popular is seq2seq-chatbot?
- tensorlayer/seq2seq-chatbot has 837 stars on GitHub.
- Where can I find seq2seq-chatbot?
- tensorlayer/seq2seq-chatbot is on GitHub at https://github.com/tensorlayer/seq2seq-chatbot.