tensorfreitas/Siamese-Networks-for-One-Shot-Learning
Teaching neural nets to recognize from a single glance
A Keras implementation of Koch et al.'s Siamese network for one-shot learning on the Omniglot dataset, with Bayesian hyperparameter tuning and honest notes on what didn't reproduce.
Not currently ranked — collecting fresh signals.
star history
What it does
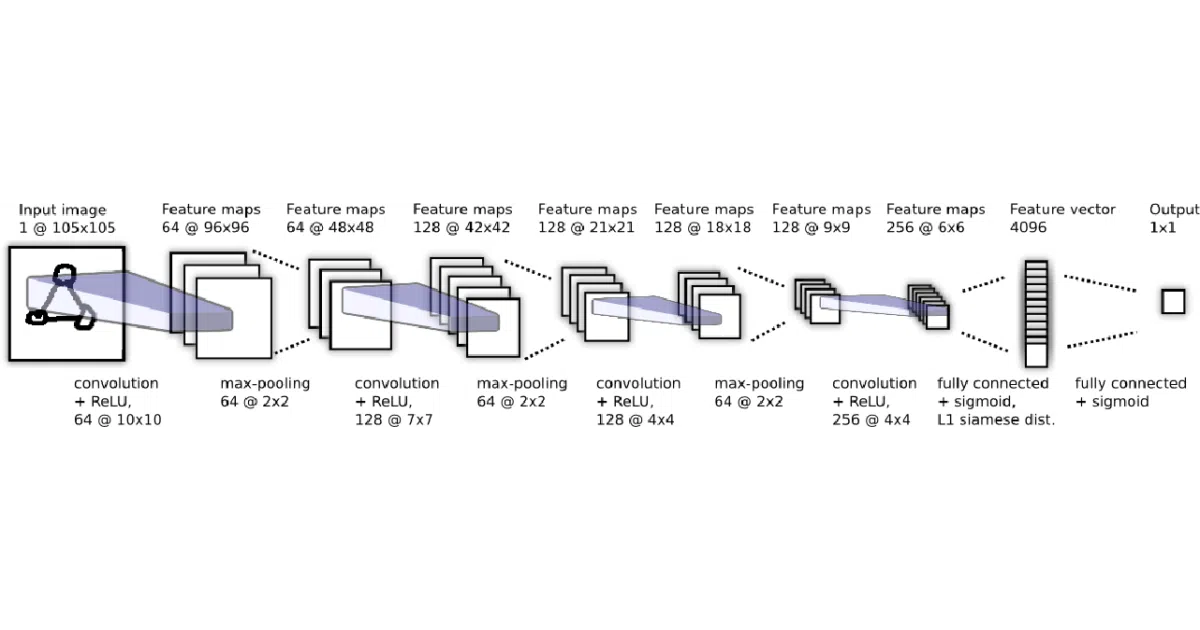
This repo implements a Siamese convolutional network that learns to judge whether two images belong to the same character class—trained on the Omniglot dataset of handwritten alphabets. At test time, it pairs a novel image against each candidate in a support set and picks the closest match, letting it classify among never-before-seen categories from a single example each.
The interesting bit
The author didn’t just port the paper; they built a custom layer-wise SGD optimizer with tunable momentum slopes and learning-rate decay schedules, then wrapped the whole thing in Bayesian hyperparameter optimization via GPyOpt. It’s the kind of thorough over-engineering that happens when someone is “familiarizing” with a topic and accidentally builds a small research framework.
Key highlights
- Reproduces the full training pipeline: data augmentation with affine distortions, pair-based verification training, and 20-way one-shot evaluation
- Custom
modified_sgdallows per-layer learning rates and momentum values that evolve across epochs - Bayesian optimization searches layer-wise hyperparameters, filter sizes, and regularization penalties
- Includes early-stopping heuristics to catch the “0.5 accuracy death spiral” from bad hyperparameter combinations
- Logs TensorBoard curves and automatically saves best models by validation one-shot accuracy
Caveats
- The author openly states they did not reproduce the paper’s >90% evaluation accuracy; they hit ~70% with SGD+momentum and ~80% with Adam, blaming hardware/time limits for incomplete Bayesian optimization runs
- The train/validation split diverges from the original paper’s protocol (24/6 from background alphabets vs. the paper’s 40/10), so numbers aren’t directly comparable
- Architecture search was skipped entirely—the “best” architecture is hardcoded from the paper
Verdict
Worth a look if you’re studying one-shot learning or need a working Keras Siamese template with hyperparameter optimization plumbing. Skip it if you need a battle-tested, paper-matching baseline; the author would tell you the same.
Frequently asked
- What is tensorfreitas/Siamese-Networks-for-One-Shot-Learning?
- A Keras implementation of Koch et al.'s Siamese network for one-shot learning on the Omniglot dataset, with Bayesian hyperparameter tuning and honest notes on what didn't reproduce.
- Is Siamese-Networks-for-One-Shot-Learning open source?
- Yes — tensorfreitas/Siamese-Networks-for-One-Shot-Learning is an open-source project tracked on heatdrop.
- What language is Siamese-Networks-for-One-Shot-Learning written in?
- tensorfreitas/Siamese-Networks-for-One-Shot-Learning is primarily written in Python.
- How popular is Siamese-Networks-for-One-Shot-Learning?
- tensorfreitas/Siamese-Networks-for-One-Shot-Learning has 624 stars on GitHub.
- Where can I find Siamese-Networks-for-One-Shot-Learning?
- tensorfreitas/Siamese-Networks-for-One-Shot-Learning is on GitHub at https://github.com/tensorfreitas/Siamese-Networks-for-One-Shot-Learning.