tensorflow/similarity
TensorFlow's kitchen-sink library for teaching models what "similar" means
A Keras-native toolkit that bundles contrastive losses, self-supervised pre-training, and nearest-neighbor indexing into one import.
Not currently ranked — collecting fresh signals.
star history
What it does
TensorFlow Similarity wraps the full metric-learning pipeline—self-supervised pre-training (SimCLR, Barlow Twins, SimSiam), supervised contrastive losses, and an in-memory nearest-neighbor index—into standard Keras model.compile() and model.fit() calls. You train embeddings instead of class labels, then query them like a search engine.
The interesting bit
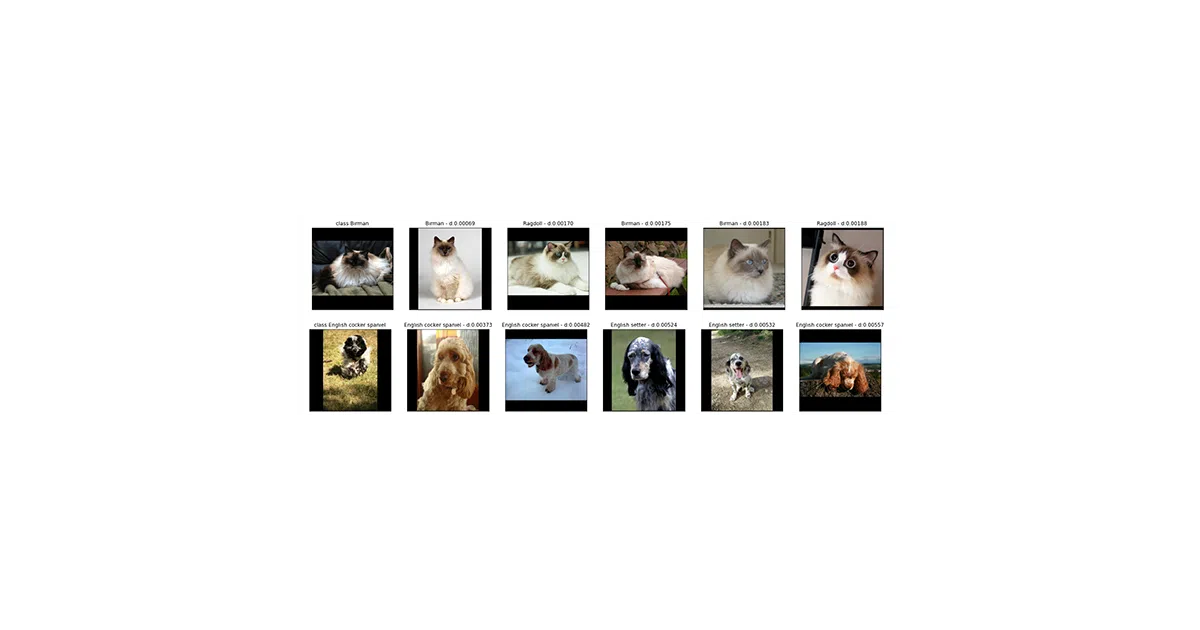
The library treats “similarity” as a first-class output type, not an afterthought. A MetricEmbedding layer enforces L2 normalization, and the SimilarityModel subclass adds .index() and .single_lookup() methods so your trained model becomes a vector search engine without leaving the notebook. The README’s cat-and-dog demo trains on a few pet breeds, then retrieves visually similar unseen breeds—showing the generalization that makes metric learning appealing in the first place.
Key highlights
- Self-supervised algorithms: SimCLR, SimSiam, Barlow Twins (plus VicReg as of v0.17)
- Supervised losses: Triplet, Multi-Similarity, Circle Loss, Soft Nearest Neighbor, and others
- Built-in samplers that balance batches for smoother contrastive training
- Retrieval metrics (Recall@K, Binary NDCG) alongside standard classification metrics
- Distributed training support for SimCLR and initial multi-modal/CLIP support
- Colab-ready notebooks for both supervised and unsupervised workflows
Caveats
- Explicitly in beta; breaking changes are expected
- Requires TensorFlow ≥2.4; the pip extra is optional if already installed
- Citation BibTeX still contains a literal “Fixme” journal field
Verdict
Worth a look if you’re already in the TensorFlow/Keras ecosystem and want to experiment with self-supervised pre-training or build a similarity search prototype without wiring together five separate libraries. PyTorch devotees or production-scale search teams will likely find the indexing too basic and the beta status too risky.
Frequently asked
- What is tensorflow/similarity?
- A Keras-native toolkit that bundles contrastive losses, self-supervised pre-training, and nearest-neighbor indexing into one import.
- Is similarity open source?
- Yes — tensorflow/similarity is open source, released under the Apache-2.0 license.
- What language is similarity written in?
- tensorflow/similarity is primarily written in Python.
- How popular is similarity?
- tensorflow/similarity has 1k stars on GitHub.
- Where can I find similarity?
- tensorflow/similarity is on GitHub at https://github.com/tensorflow/similarity.