taki0112/Densenet-Tensorflow
DenseNet in TF 1.x: a readable paper re-implementation
A straightforward TensorFlow 1.x implementation of the DenseNet paper, aimed at developers who want to see the architecture in code rather than equations.
Not currently ranked — collecting fresh signals.
star history
What it does
Implements the DenseNet architecture from the 2016 paper for image classification on CIFAR-10, CIFAR-100, MNIST, and ImageNet. The core logic lives in a single Densenet.py file with explicit dense blocks, bottleneck layers, and transition layers spelled out in plain TensorFlow.
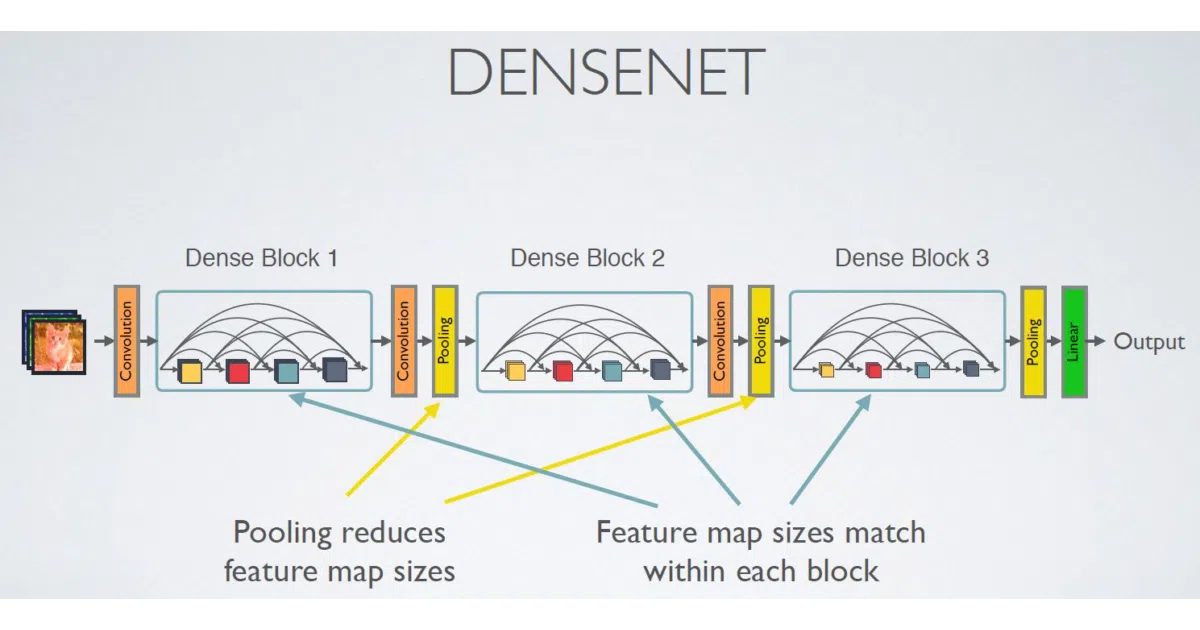
The interesting bit
The author swaps the original paper’s optimizer for Adam and walks through each architectural concept—global average pooling, dense connectivity, bottleneck layers—with both a diagram and the matching code block. It reads more like a dissected notebook than a black-box library.
Key highlights
- Self-contained: one main Python file with the full network definition
- Includes a from-scratch
Global_Average_Poolingimplementation usingtf.layers.average_pooling2d, plus an optionaltflearnshortcut - Achieves 99.2% on MNIST without dropout (though the CIFAR/ImageNet result numbers in the README are just pasted benchmark tables, not this implementation’s scores)
- Explicit batch normalization setup using
tf.contrib.layers.batch_normwith training/inference branching - GPU memory workaround documented: switch to
allow_soft_placement=Trueif needed
Caveats
- Locked to TensorFlow 1.x and
tf.contribAPIs that are deprecated or removed in TF 2.x - The CIFAR-10/100 and ImageNet result images appear to be general benchmark tables, not actual training logs from this repo
- Four dense blocks hardcoded; the layer counts per block (6→12→48→32) from the paper are flattened to 4 each in one shown snippet, so it’s unclear which configuration produced the MNIST result
Verdict
Worth a look if you’re studying DenseNet and want to trace data flow through concatenation layers in readable TF 1.x code. Skip it if you need a maintained, production-ready model—this is a frozen-in-time educational implementation.
Frequently asked
- What is taki0112/Densenet-Tensorflow?
- A straightforward TensorFlow 1.x implementation of the DenseNet paper, aimed at developers who want to see the architecture in code rather than equations.
- Is Densenet-Tensorflow open source?
- Yes — taki0112/Densenet-Tensorflow is open source, released under the MIT license.
- What language is Densenet-Tensorflow written in?
- taki0112/Densenet-Tensorflow is primarily written in Python.
- How popular is Densenet-Tensorflow?
- taki0112/Densenet-Tensorflow has 502 stars on GitHub.
- Where can I find Densenet-Tensorflow?
- taki0112/Densenet-Tensorflow is on GitHub at https://github.com/taki0112/Densenet-Tensorflow.