sunnweiwei/RankGPT
Teaching ChatGPT to sort search results, one permutation at a time
An EMNLP 2023 Outstanding Paper that treats LLMs as ranking agents rather than answer generators, with a clever sliding-window hack to beat context limits.
Not currently ranked — collecting fresh signals.
star history
What it does
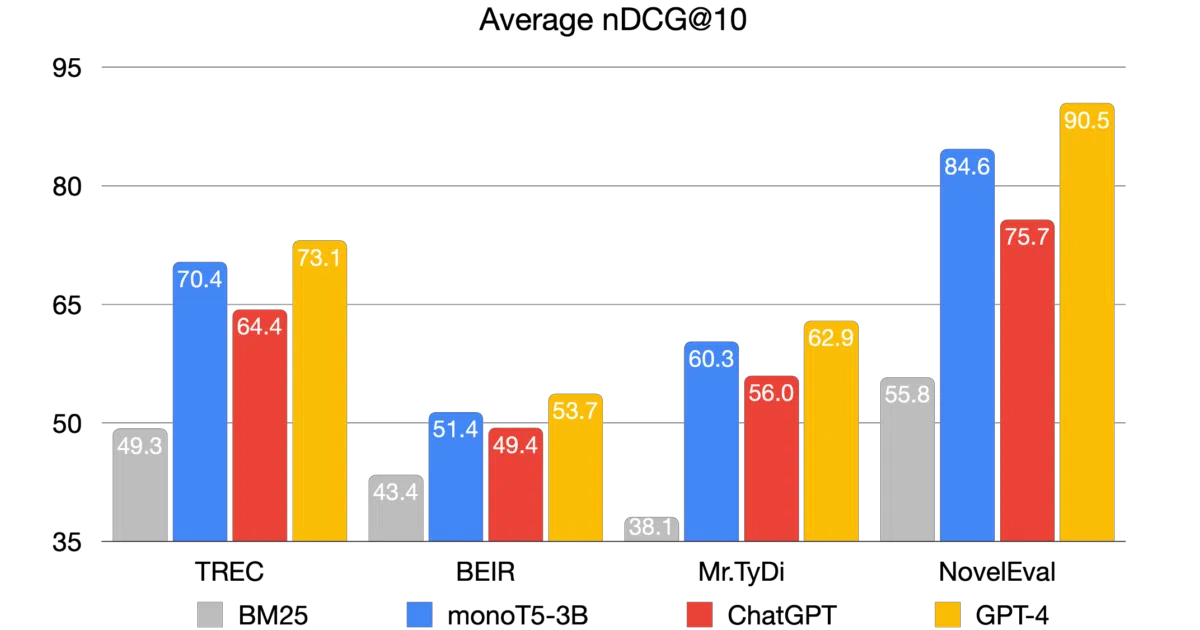
RankGPT reframes search re-ranking as a permutation problem: instead of scoring passages individually, it asks ChatGPT or GPT-4 to output the correct order of candidate passages for a query. The repo provides a lightweight pipeline, sliding-window strategy for long lists, and evaluation scripts against standard IR benchmarks.
The interesting bit
The sliding window trick is the real mechanic. LLMs have token ceilings; you can’t feed them 100 passages at once. RankGPT ranks from back to front in overlapping windows (e.g., size 20, step 10), letting the model iteratively bubble the best results upward without ever seeing the full list simultaneously. It’s bubble sort with an API key.
Key highlights
- Won EMNLP 2023 Outstanding Paper; code matches the published work
- Supports multiple backends via LiteLLM (Azure, Claude, Cohere, Llama2)
- Includes 100K ChatGPT-generated permutations on MS MARCO for training smaller models
- Provides a “NovelEval” test set designed to evade LLM training-data contamination
- Ships with pyserini integration for end-to-end retrieval-to-rerank evaluation
Caveats
- Core dependency on proprietary APIs (OpenAI, etc.) for the actual ranking; open-source LLMs only enter via a later “Instruction Distillation” add-on
- README truncates mid-table for the 100K dataset links, so some download details are cut off
Verdict
Worth a look if you build search pipelines and wonder whether LLMs can replace your learned ranker. Skip it if you need a fully open, production-ready reranker without API costs or latency concerns.
Frequently asked
- What is sunnweiwei/RankGPT?
- An EMNLP 2023 Outstanding Paper that treats LLMs as ranking agents rather than answer generators, with a clever sliding-window hack to beat context limits.
- Is RankGPT open source?
- Yes — sunnweiwei/RankGPT is open source, released under the Apache-2.0 license.
- What language is RankGPT written in?
- sunnweiwei/RankGPT is primarily written in Python.
- How popular is RankGPT?
- sunnweiwei/RankGPT has 669 stars on GitHub.
- Where can I find RankGPT?
- sunnweiwei/RankGPT is on GitHub at https://github.com/sunnweiwei/RankGPT.