sjtu-marl/malib
Population-based MARL that doesn't melt your laptop
MALib wraps PSRO, self-play, and distributed MARL into a Ray-backed framework with a surprisingly sane API.
Not currently ranked — collecting fresh signals.
star history
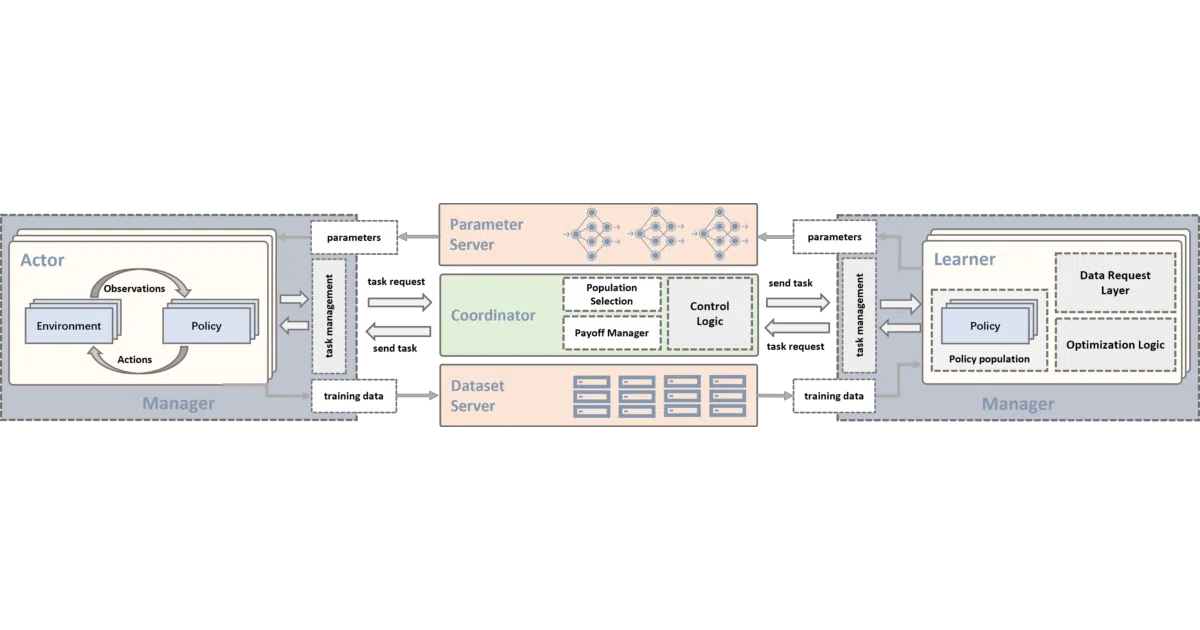
What it does MALib is a Python framework for population-based multi-agent reinforcement learning. It bundles algorithms like Policy Space Response Oracle (PSRO), Self-Play, and Neural Fictitious Self-Play, and runs them distributed via Ray. It also wraps a menagerie of environments—OpenSpiel, SMAC, PettingZoo, Google Research Football, and standard Gym—so you aren’t stuck implementing yet another StarCraft II parser.
The interesting bit The framework treats population-based training as a first-class abstraction, not a bolt-on. It separates “scenarios” (PSRO, MARL, etc.) from the underlying distributed execution, so the same algorithm code can move between local debugging and cluster deployment without rewriting. That’s the kind of separation that usually collapses in practice; here it’s actually documented.
Key highlights
- First-class support for PSRO and self-play variants, plus standard distributed MARL
- Built on Ray for parallelization; abstracts away the distributed-vs-local distinction
- Environment integrations: OpenSpiel, Gym, SMAC, PettingZoo, Google Research Football
- Published in JMLR (2023), which suggests the authors survived peer review
- Linux-only; Python 3.8+; conda recommended
Caveats
- Linux-only, so Windows and macOS users are out of luck
- Multi-stream PSRO scenario is listed but unchecked—still in progress
- DexterousHands integration is also pending
Verdict Worth a look if you’re doing game-theoretic MARL research and need PSRO or self-play without building the population infrastructure yourself. Skip if you’re on Windows, or if your multi-agent needs are satisfied by a few parallel PPO runs.
Frequently asked
- What is sjtu-marl/malib?
- MALib wraps PSRO, self-play, and distributed MARL into a Ray-backed framework with a surprisingly sane API.
- Is malib open source?
- Yes — sjtu-marl/malib is open source, released under the MIT license.
- What language is malib written in?
- sjtu-marl/malib is primarily written in Python.
- How popular is malib?
- sjtu-marl/malib has 553 stars on GitHub.
- Where can I find malib?
- sjtu-marl/malib is on GitHub at https://github.com/sjtu-marl/malib.