simchowitzlabpublic/nano-world-model
A world model you can actually train on one GPU
Nano World Model strips diffusion-forcing video prediction down to a clean, reproducible codebase with pretrained checkpoints for robot manipulation, CSGO, and RT-1.
Not currently ranked — collecting fresh signals.
star history
What it does
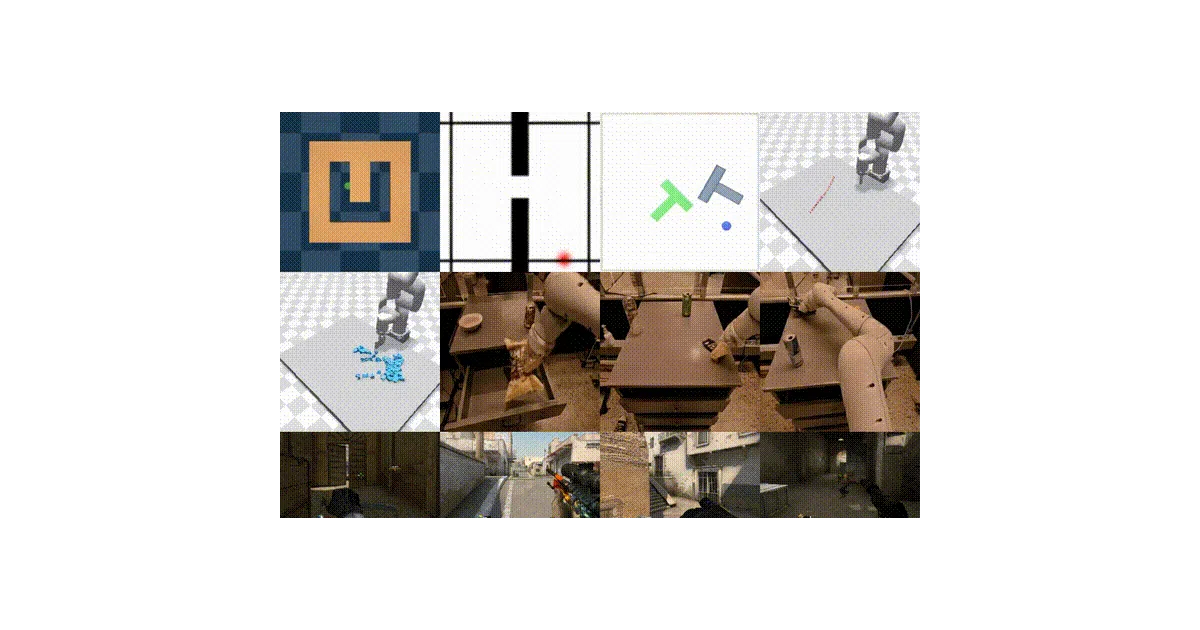
Trains video world models using diffusion-forcing — predict future frames conditioned on actions, then roll out autoregressively for planning or generation. Ships with configs for DINO-WM robot tasks, CSGO gameplay, and RT-1 fractal data. Everything runs through a single Hydra-managed pipeline: train, validate, evaluate, checkpoint.
The interesting bit
The “nano” framing isn’t just branding. The repo deliberately follows Karpathy’s NanoGPT philosophy: minimal dependencies, one obvious way to do things, and full ablation tables published alongside checkpoints. They actually tell you which design choices matter — prediction target (pred-v vs. pred-x0), action injection method, noise schedule — with head-to-head numbers in the docs.
Key highlights
- Pretrained checkpoints for 7 domains on HuggingFace, from 15k to 300k steps
- Quantitative evaluation included: PSNR, SSIM, LPIPS, FID on 256 fixed samples with reported methodology
- Built-in applications beyond generation: MPC-style planning with CEM, video-to-3D point cloud reconstruction via Depth Anything 3
- Clean config system with environment-variable path overrides; clone-to-rollout in minutes per the README
- Full training and ablation documentation, not just a paper supplement
Caveats
- CSGO and RT-1 datasets require separate downloads; setup isn’t fully self-contained
- The “instant start” claim assumes you’ve already handled conda, dataset paths, and a 1.1GB i3d torchscript download for evaluation
Verdict
Worth a look if you’re doing robot learning, model-based RL, or diffusion-forcing research and need a reproducible baseline to fork. Skip if you want a hosted API or plug-and-play web demo — this is training infrastructure, not a product.
Frequently asked
- What is simchowitzlabpublic/nano-world-model?
- Nano World Model strips diffusion-forcing video prediction down to a clean, reproducible codebase with pretrained checkpoints for robot manipulation, CSGO, and RT-1.
- Is nano-world-model open source?
- Yes — simchowitzlabpublic/nano-world-model is open source, released under the MIT license.
- What language is nano-world-model written in?
- simchowitzlabpublic/nano-world-model is primarily written in Python.
- How popular is nano-world-model?
- simchowitzlabpublic/nano-world-model has 690 stars on GitHub.
- Where can I find nano-world-model?
- simchowitzlabpublic/nano-world-model is on GitHub at https://github.com/simchowitzlabpublic/nano-world-model.