showlab/Code2Video
Teaching machines to teach: code-first video generation
An agentic framework that generates educational videos by writing Manim code instead of hallucinating pixels.
Not currently ranked — collecting fresh signals.
star history
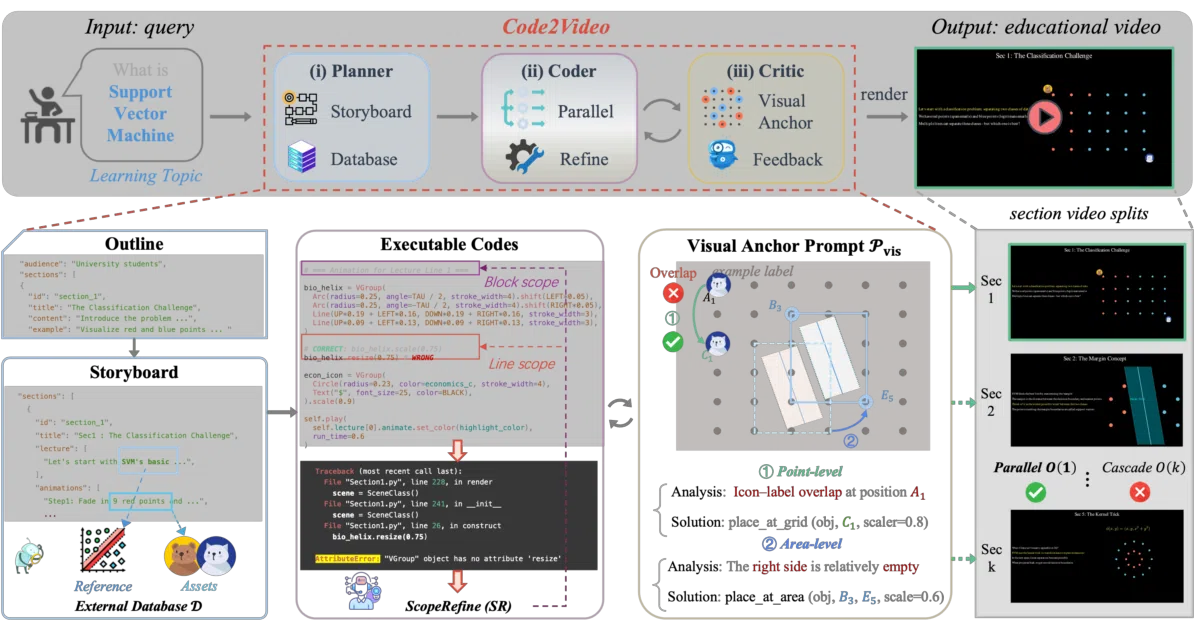
What it does Code2Video takes a knowledge point—say, “linear transformations and matrices”—and spins up a trio of LLM agents to plan, code, and critique a Manim animation. The output is a reproducible, executable video script rather than a black-box generative video. It ships with the MMMC benchmark, 117 curated topics inspired by 3Blue1Brown, and evaluation tools that measure whether viewers actually learn from the result.
The interesting bit The bet here is structural: by generating code instead of pixels, the system gets temporal sequencing and spatial layout “for free” through Manim’s execution model. The README’s side-by-side GIFs suggest this outperforms Veo3 and Wan2.2 on clarity for topics like the Towers of Hanoi or Fourier series—though the authors wisely credit 3Blue1Brown as the “upper bound” they’re chasing.
Key highlights
- Tri-agent architecture: Planner (storyboard), Coder (Manim synthesis), Critic (layout refinement with anchor points)
- Requires multiple paid APIs: Claude-4-Opus for code quality, Gemini-2.5-pro for visual critique, plus optional ICONFINDER for assets
- Benchmark evaluates knowledge transfer (TeachQuiz), aesthetics (AES), and token/time efficiency
- ICML 2026 acceptance; 1,786 stars and climbing
- Installation time dropped 80–90% after a community contribution to requirements.txt
Caveats
- The ICONFINDER integration is currently broken; icons are temporarily pulled from a HuggingFace dataset mirror
- Best results depend on top-tier API access (Claude-4-Opus, Gemini-2.5-pro), so costs scale with ambition
Verdict Worth a look if you’re building educational content pipelines or researching structured video generation. Skip it if you need casual, one-shot video from a text prompt—this is a research system with API bills attached.
Frequently asked
- What is showlab/Code2Video?
- An agentic framework that generates educational videos by writing Manim code instead of hallucinating pixels.
- Is Code2Video open source?
- Yes — showlab/Code2Video is open source, released under the MIT license.
- What language is Code2Video written in?
- showlab/Code2Video is primarily written in Python.
- How popular is Code2Video?
- showlab/Code2Video has 1.8k stars on GitHub.
- Where can I find Code2Video?
- showlab/Code2Video is on GitHub at https://github.com/showlab/Code2Video.