shibing624/pytextclassifier
A text-classifier buffet: from logistic regression to BERT
One Python toolkit that wraps classical ML, deep learning, and transformers behind a uniform API so you can swap algorithms without rewriting plumbing.
Not currently ranked — collecting fresh signals.
star history
What it does
pytextclassifier is a Python toolkit that trains and runs text classifiers across a wide range of algorithms—logistic regression, random forest, XGBoost, SVM, TextCNN, TextRNN, FastText, and BERT variants—through a consistent interface. It handles binary, multi-class, multi-label, and hierarchical classification, plus K-means clustering, for both Chinese and English text.
The interesting bit
The value is in the boring part: the API stays the same whether you’re calling a sklearn logistic regression or a GPU-hungry BERT model. The README shows identical train(), predict(), and evaluate_model() patterns across all backends, which means you can benchmark a cheap baseline against a transformer without rewriting data pipelines.
Key highlights
- Broad algorithm coverage: 11 classifiers from classical ML to deep learning and transformers (BERT, ALBERT, RoBERTa, XLNet)
- Unified interface:
ClassicClassifier,FastTextClassifier,BertClassifier, etc. all expose the same core methods - Chinese-first but bilingual: examples and stopword handling for both Chinese and English corpora
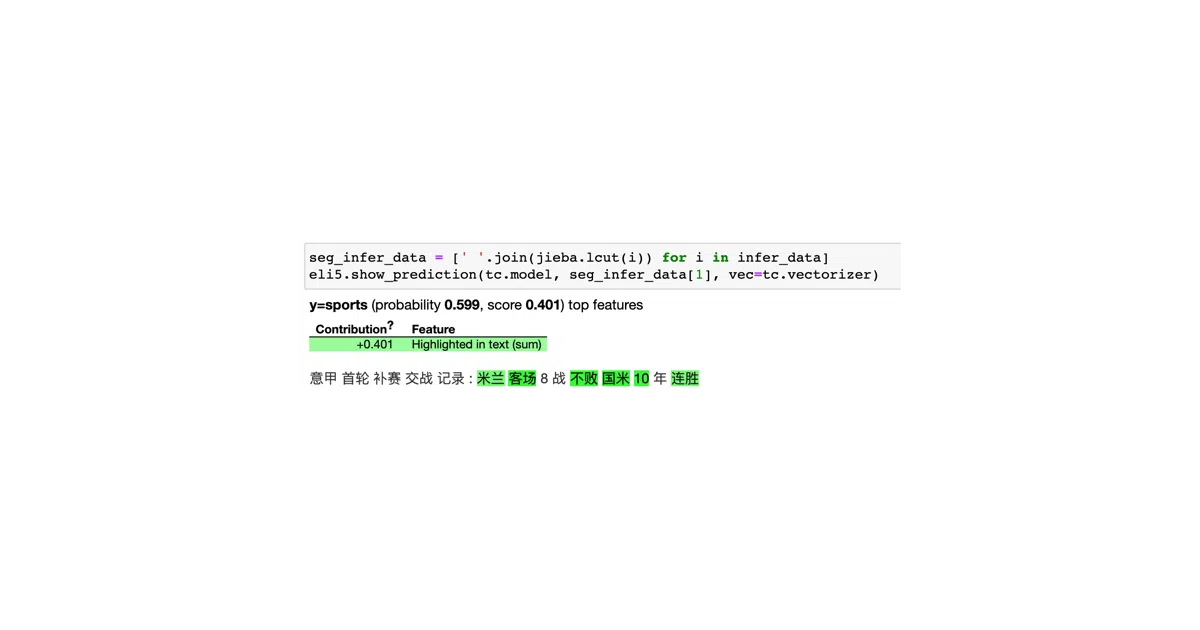
- Feature inspection: built-in eli5 integration to visualize feature weights for interpretable models
- Lazy model loading: models load on demand rather than at import time
Caveats
- Documentation is sparse on performance numbers, hardware requirements, or how well each model scales; you’ll need to benchmark yourself
- The deep-learning examples show toy datasets with perfect accuracy—real-world behavior is unclear from the README
Verdict
Worth a look if you need to prototype text classifiers fast across multiple algorithm families, especially for Chinese text. Skip it if you want a single SOTA model with heavy optimization; this is a breadth-over-depth toolbox.
Frequently asked
- What is shibing624/pytextclassifier?
- One Python toolkit that wraps classical ML, deep learning, and transformers behind a uniform API so you can swap algorithms without rewriting plumbing.
- Is pytextclassifier open source?
- Yes — shibing624/pytextclassifier is open source, released under the Apache-2.0 license.
- What language is pytextclassifier written in?
- shibing624/pytextclassifier is primarily written in Python.
- How popular is pytextclassifier?
- shibing624/pytextclassifier has 524 stars on GitHub.
- Where can I find pytextclassifier?
- shibing624/pytextclassifier is on GitHub at https://github.com/shibing624/pytextclassifier.