sdv-dev/Copulas
Statistical forgery: generating fake data that actually behaves like the real thing
Copulas models the hidden relationships between variables so your synthetic data preserves correlations, not just individual column distributions.
Not currently ranked — collecting fresh signals.
star history
What it does
Copulas is a Python library for modeling multivariate distributions and sampling synthetic data from them. Feed it a table of numerical data, pick a copula function (Gaussian, Archimedean, or Vine), and it learns the joint statistical behavior — then generates new rows that mimic the original relationships, not just column-by-column histograms.
The interesting bit
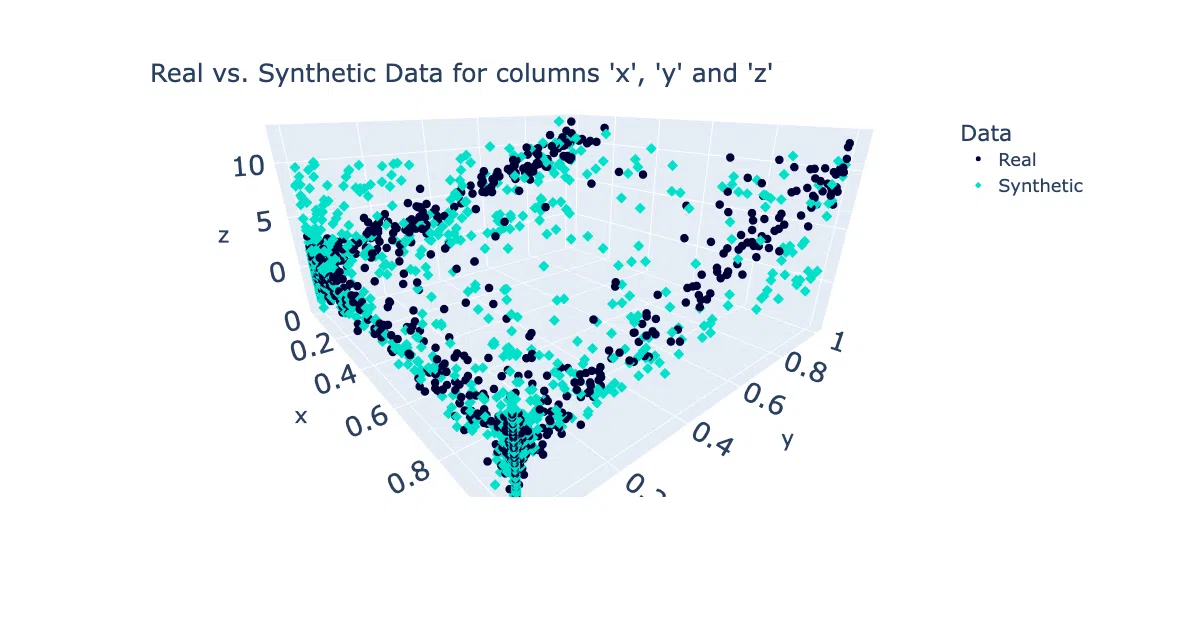
The library exposes the full internals of its models, so you can inspect and tweak learned parameters rather than treating it as a black box. It also ships with built-in 1D, 2D, and 3D visualizations to eyeball whether your synthetic data actually matches the real stuff — a sanity check that too many generative tools skip.
Key highlights
- Supports Gaussian, Archimedean, and Vine copulas for different dependency structures
- Built-in visualization suite: histograms, 2D scatterplots, and 3D scatterplots for comparing real vs. synthetic
- Full parameter access: inspect and manually adjust fitted model internals
- Part of the broader SDV (Synthetic Data Vault) ecosystem from DataCebo, originally started at MIT’s Data to AI Lab in 2018
- Available via pip and conda-forge
Caveats
- Marked as “Pre-Alpha” development status, so expect API instability
- README focuses on numerical data; unclear how it handles categorical columns or mixed types without preprocessing
Verdict
Worth a look if you need statistically grounded synthetic tabular data and want visibility into how the sausage is made. Skip it if you need production-grade stability today or deep learning-based generation out of the box — the SDV umbrella package may be the better entry point.
Frequently asked
- What is sdv-dev/Copulas?
- Copulas models the hidden relationships between variables so your synthetic data preserves correlations, not just individual column distributions.
- Is Copulas open source?
- Yes — sdv-dev/Copulas is an open-source project tracked on heatdrop.
- What language is Copulas written in?
- sdv-dev/Copulas is primarily written in Python.
- How popular is Copulas?
- sdv-dev/Copulas has 647 stars on GitHub.
- Where can I find Copulas?
- sdv-dev/Copulas is on GitHub at https://github.com/sdv-dev/Copulas.