salesforce/warp-drive
Reinforcement learning that finally stops nagging your CPU
A Salesforce research framework that runs entire multi-agent RL pipelines on the GPU, eliminating the CPU-GPU shuttle service that usually bottlenecks training.
Not currently ranked — collecting fresh signals.
star history
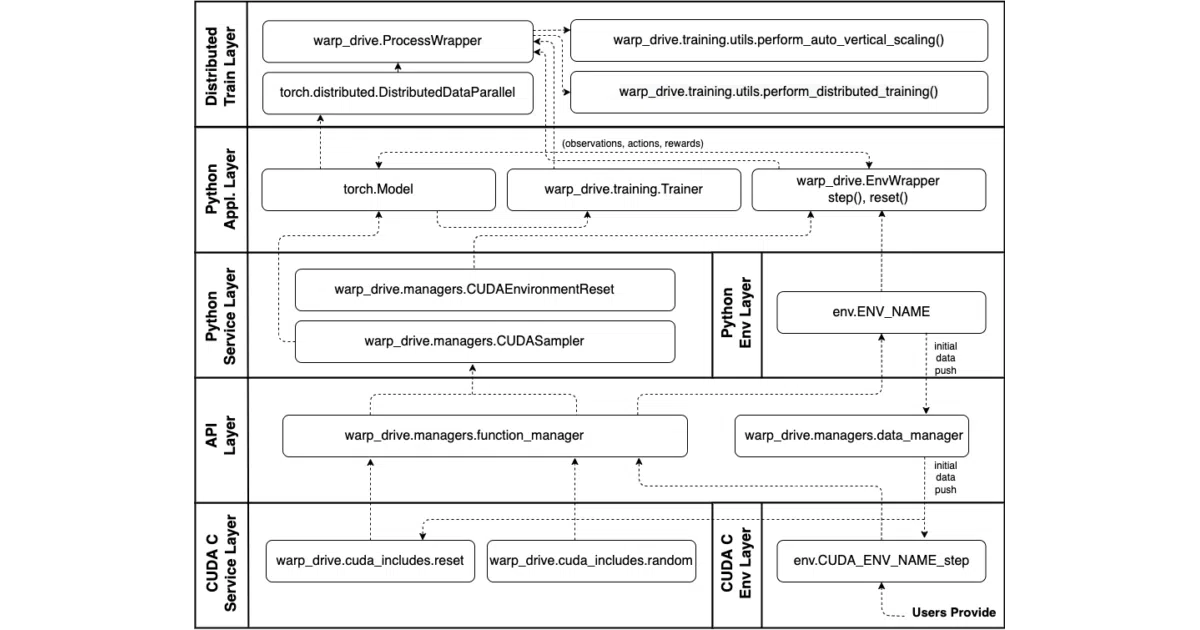
What it does WarpDrive is a multi-agent reinforcement learning framework that keeps everything—simulation and training—on the GPU. No more copying tensors back and forth to a CPU that mostly just overheats and complains. It supports single-agent setups too, but its sweet spot is hundreds or thousands of agents interacting in parallel environment replicas.
The interesting bit The whole environment step runs in CUDA C or Numba, not Python. You write one GPU kernel for your environment dynamics; the rest—PPO, A2C, DDPG, PyTorch optimizers—stays in familiar Python. The README claims “at least 100x throughput over CPU-based counterparts,” and while that number likely depends on your specific workload, the architecture itself (no CPU-GPU memory copies, parallel agents across blocks) is where the speedup actually comes from.
Key highlights
- Supports up to 1,024 agents per environment, 1,000+ environments per GPU, and distributed runs across 2–16 GPU nodes
- Environment backends: raw CUDA C or JIT-compiled Numba; training backend is PyTorch
- On-policy (A2C, PPO) since v1.0; off-policy DDPG and continuous actions added in v2.7
- Auto-scaling and multi-GPU support from v1.3/v1.4 onward
- Includes reference environments: multi-agent “Tag,” classic control, COVID-19 economic simulations, climate policy, and catalytic reaction pathway search
- Published in JMLR 2022; used in at least one Nature Communications paper
Caveats
- You need a GPU with nvcc or Numba support; this is not CPU-fallback friendly
- Custom environments require writing CUDA C or Numba step functions—there is no pure-Python escape hatch for the simulation itself
- The “100x” and “millions of steps per second” claims are from specific Tag benchmarks; your mileage will vary with environment complexity
Verdict Worth a look if you’re already GPU-bound and need to scale multi-agent RL beyond what CPU simulation can feed to your GPUs. Skip it if your environments are simple enough that CPU overhead isn’t your bottleneck, or if your team lacks anyone comfortable with CUDA/Numba kernel debugging.
Frequently asked
- What is salesforce/warp-drive?
- A Salesforce research framework that runs entire multi-agent RL pipelines on the GPU, eliminating the CPU-GPU shuttle service that usually bottlenecks training.
- Is warp-drive open source?
- Yes — salesforce/warp-drive is open source, released under the BSD-3-Clause license.
- What language is warp-drive written in?
- salesforce/warp-drive is primarily written in Python.
- How popular is warp-drive?
- salesforce/warp-drive has 503 stars on GitHub.
- Where can I find warp-drive?
- salesforce/warp-drive is on GitHub at https://github.com/salesforce/warp-drive.