salesforce/pytorch-qrnn
An LSTM that learned to stop waiting for itself
Salesforce's QRNN trades some recurrence for massive parallelism, claiming 2–17× speedups over cuDNN LSTM with similar accuracy.
Not currently ranked — collecting fresh signals.
star history
What it does
The Quasi-Recurrent Neural Network (QRNN) is a drop-in PyTorch replacement for LSTM/GRU layers. It keeps comparable accuracy but restructures the computation so most work happens in large, parallelizable matrix multiplications rather than timestep-by-timestep recurrence. The actual hidden-state update is reduced to a fast element-wise op called ForgetMult.
The interesting bit
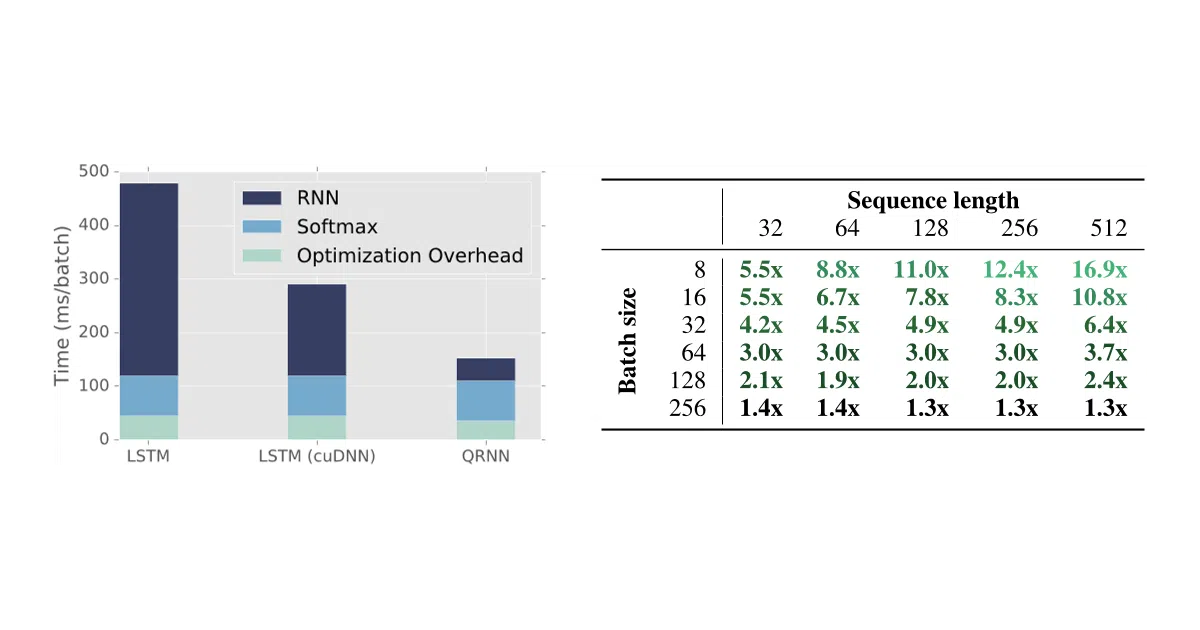
The speedup isn’t from better CUDA kernels for the same algorithm—it’s from changing the math so the problem becomes embarrassingly parallel. The README notes the biggest wins come exactly where LSTMs hurt most: small batches or long sequences, where cuDNN’s sequential dependency chain wastes GPU capacity.
Key highlights
- Claims 2–17× faster than NVIDIA’s cuDNN LSTM depending on batch size and sequence length
- Near drop-in API: swap
nn.LSTMforQRNNin “many standard use cases” - Ships with custom CUDA kernel via CuPy/pynvrtc; CPU fallback exists but isn’t the point
- Includes
ForgetMultas a standalone fast recurrence primitive for other architectures - Multi-GPU
DataParallelsupport added; used in Salesforce’s AWD-LSTM-LM language modeling codebase
Caveats
- Bidirectional QRNN is explicitly not supported yet (requires a backward
ForgetMultkernel) - No
PackedSequencesupport for variable-length sequences - Convolutional windows currently limited to size 1 or 2
- Dependencies are nontrivial: needs CuPy and pynvrtc on top of PyTorch
Verdict
Worth a look if you’re training RNNs on long sequences or with small batch sizes and can live without bidirectionality. If you need standard packed sequences or modern Transformer-class throughput, this is a detour, not a destination.
Frequently asked
- What is salesforce/pytorch-qrnn?
- Salesforce's QRNN trades some recurrence for massive parallelism, claiming 2–17× speedups over cuDNN LSTM with similar accuracy.
- Is pytorch-qrnn open source?
- Yes — salesforce/pytorch-qrnn is open source, released under the BSD-3-Clause license.
- What language is pytorch-qrnn written in?
- salesforce/pytorch-qrnn is primarily written in Python.
- How popular is pytorch-qrnn?
- salesforce/pytorch-qrnn has 1.3k stars on GitHub.
- Where can I find pytorch-qrnn?
- salesforce/pytorch-qrnn is on GitHub at https://github.com/salesforce/pytorch-qrnn.